
Cuando nos enfrentamos a la tesitura de una migración de SQL Server a versiones más recientes, entramos en la incertidumbre de si esta operación, que en muchos de los casos pudiera ser costosa, va a proporcionar unos beneficios que justifiquen dicho esfuerzo.
En este artículo te mostraremos las principales novedades que introducen las SQL Server 2019/2022. Nos centraremos, principalmente, en las novedades incluidas en Intelligent Query Processing (IQP).
Como veremos en el desarrollo del post, la mayoría de novedades que se describen no llevan asociadas esfuerzos adicionales a nivel de desarrollo y están listas para ser utilizadas.
Si estás en esa fase de incertidumbre, esperamos que te sirva para tomar la decisión de realizar la migración o, si aún no te lo has planteado, trates de evaluar la opción con esto que te contamos.
Intelligent Query Processing (IQP)
Intelligent query processing es una característica que se introdujo en SQL Server 2019 y que ha sido evolucionada en SQL Server 2022. Dicha característica incluye un modelo de procesamiento que mejoran el rendimiento de las cargas de trabajo existentes con un esfuerzo de implementación mínimo.
Vamos a analizar las principales características incluidas en IQP:
- Batch Mode on rowstore (2019+)
Batch Mode on rowstore nos permite la ejecución de nuestras consultas en modo batch (procesamiento en bloques de 900 filas) y sin necesidad de índices columnares.
- Scalar UDF Inlining (2019+)
Muchos hemos sufrido el rendimiento de funciones escalares.

En versiones posteriores a SQL Server 2019, las funciones escalares se transforman en expresiones relacionales equivalentes que se “insertan” en la consulta que realiza la llamada, lo que a menudo supone una notable mejora del rendimiento.
- Table Variable Deferred Compilation (2019+)
En versiones previas a SQL Server 2019, las variables tipo tabla no disponían de estadísticas que pudieran favorecer la generación de un plan de ejecución eficiente.

Las versiones SQL Server 2019/2022 usan la cardinalidad real de la variable de tabla encontrada en la primera compilación en lugar de una estimación fija como ocurría en versiones anteriores.
- Cardinal estimator feedback (2022+)
Cardinal estimator feedback es una nueva característica introducida en SQL Server 2022 que permite identificar y corregir los planes de ejecución ineficientes en consultas de mucho uso, con errores en la estimación de la cardinalidad.
- Memory grant feedback (2019+)
Memory grant feedback es una característica introducida por SQL Server 2019 y mejorada en SQL Server 2022. Dicha característica detecta aquellas consultas que hacen uso de espacio en la tempdb, modificando la asignación de memoria para evitar esa operación.
- Parameter Sensitivity Plan Optimization (2022+)
Parameter Sensitivity Plan Optimization aborda el escenario en el que un único plan almacenado en caché para una consulta con parámetros no es óptimo para todos los valores de parámetro entrantes posibles, por ejemplo, distribuciones de datos no uniformes que es, en gran medida, el escenario que se da con parameter sniffing.
Para estos casos, SQL Server 2022 habilita automáticamente varios planes activos almacenados en caché para la misma consulta parametrizada. Estos planes de ejecución admiten distinta cardinalidad en función de la llamada que se esté ejecutando.
- Mejoras en el acceso concurrente a archivos del sistema (2022+)
Esta característica minimiza las esperas de page latch asociadas al acceso simultaneo que provocan contención en las estructuras de datos.
A continuación, veremos un ejemplo del comportamiento de una de las características más algunas importantes introducidas en SQL Server 2022, Parameter Sensitivity Plan Optimization, que nos hubiera evitado malos ratos en el pasado.
Parameter Sensitivity Plan Optimization (2022+)
Identificación del problema
Como vimos en el apartado anterior, la característica Parameter Sensitivity Plan Optimization aborda el escenario en el que un único plan almacenado en caché para una consulta con parámetros no es óptimo para todos los valores de parámetro entrantes posibles, por ejemplo, distribuciones de datos no uniformes que es, en gran medida, el escenario que se da con parameter sniffing. Veamos un ejemplo sobre la base de datos WideWorldImporters, que puedes descargar en el siguiente link: Release Wide World Importers sample database v1.0 · microsoft/sql-server-samples · GitHub:
En primer lugar preparamos el entorno. Ojo con el procedimiento almacenado GetStockItemsbySupplier en el que vamos a forzar una consulta sobre el campo SupplierID que contiene información con cardinalidad desigual.
-- Reconstruimos el índice que vamos a utilizar posteriormente en la demo (FK_Warehouse_StockItems_SupplierID ON Warehouse.StockItems)
USE WideWorldImporters;
GO
ALTER INDEX FK_Warehouse_StockItems_SupplierID ON Warehouse.StockItems REBUILD;
GO
-- Creamos el procedimiento almacenado GetStockItemsbySupplier
USE WideWorldImporters;
GO
CREATE OR ALTER PROCEDURE [Warehouse].[GetStockItemsbySupplier] @SupplierID int
AS
BEGIN
SELECT StockItemID, SupplierID, StockItemName, TaxRate, LeadTimeDays
FROM Warehouse.StockItems s
WHERE SupplierID = @SupplierID
ORDER BY StockItemName;
END;
GO
-- Forzamos el comportamiento en versiones anteriores a SQL Server 2022
USE WideWorldImporters;
GO
ALTER DATABASE current SET COMPATIBILITY_LEVEL = 150;
GO
ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE;
GO
ALTER DATABASE current SET QUERY_STORE CLEAR;
GO
Debido a la distribución de la cardinalidad del campo SupplierID, se observa un comportamiento dispar en función del valor del parámetro que se le pasa al procedimiento almacenado. Veámoslo:
-- Revisar Index Seek en plan de ejecución para @SupplierID=2
USE WideWorldImporters;
GO
SET STATISTICS TIME ON;
GO
-- SQL Server Execution Times: CPU time = 0 ms, elapsed time = 5 ms.
-- The best plan for this parameter is an index seek
EXEC Warehouse.GetStockItemsbySupplier 2;
GO
Por la baja cardinalidad de @SupplierID=2, el motor entiende que la mejor opción es hacer uso de un index seek. La consulta se ejecuta en apenas 5 ms.
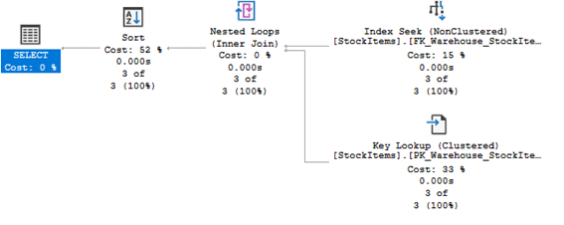
Veamos qué pasa para valores de SupplierID de mayor cardinalidad:
USE WideWorldImporters;
GO
SET STATISTICS TIME ON;
GO
-- SQL Server Execution Times: CPU time = 46610 ms, elapsed time = 169484 ms.
-- ¿The best plan for this parameter is an index seek?
EXEC Warehouse.GetStockItemsbySupplier 4;
GO
Para SuppliedID=4 los tiempos se disparan a 2,5 minutos. Esto es debido a que el plan de la ejecución anterior ha sido cacheado y reutilizado. El operador index seek es muy costoso para grandes volumetrías de datos y, en este caso, hubiera convenido hacer uso de un recorrido del índice (index scan) frente a un index seek.
Probemos a borrar el caché plan y comprobemos el plan de ejecución por el que hubiera optado el motor en caso de recompilación para SuppliedID=4.
USE WideWorldImporters;
GO
set statistics time on
GO
ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE;
GO
-- The best plan for this parameter is an index scan
EXEC Warehouse.GetStockItemsbySupplier 4;
GO
De esta forma puede comprobarse que, según el valor del parámetro, necesitará planes distintos para una ejecución eficiente.
Solución aportada por SQL Server 2022
Para estos casos, SQL Server 2022 habilita automáticamente varios planes activos almacenados en caché para la misma consulta parametrizada. Estos planes de ejecución admiten distinta cardinalidad en función de la llamada que se esté ejecutando. Veamos cómo lo hace:
En primer lugar, limpiamos planes de ejecución cacheados y cambiamos el modo de compatibilidad a SQL Server 2022 (compatibility level = 16).
USE WideWorldImportersSummit;
GO
ALTER DATABASE CURRENT SET COMPATIBILITY_LEVEL = 160;
GO
ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE;
GO
ALTER DATABASE CURRENT SET QUERY_STORE CLEAR;
GO
En este caso hemos de abrir dos sesiones distintas, una para ejecutar con @SupplierID=2 y otra para ejecutar con @SupplierID=4. Pasaremos a ejecutarlas y comprobar que, para cada caso, se generan planes de ejecución distintos.
-- Sesión 1: @SupplierID=4
USE WideWorldImportersSummit;
GO
set statistics time on
GO
-- The best plan for this parameter is an index scan
EXEC Warehouse.GetStockItemsbySupplier 4;
GO

-- Sesión 2: @SupplierID=2
USE WideWorldImportersSummit;
GO
set statistics time on
GO
-- The best plan for this parameter is an index seek
EXEC Warehouse.GetStockItemsbySupplier 2;
GO
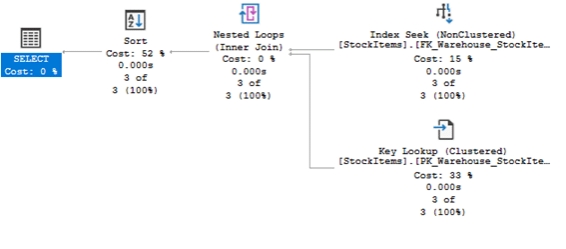
Con esta demo podréis comprobar que, para cada ejecución, se han generado planes de ejecución ajustados a la cardinalidad.
Desde Verne Tech podemos ayudarte con soluciones y servicios de SQL Server.
Habla con uno de nuestros técnicos y cuéntanos las necesidades de tu empresa.
Conclusiones
En este post hemos desarrollado de forma general algunas de las características que se incorporan en SQL Server 2019/2022. Trata de evaluar cada una de ellas, porque posiblemente eches de menos alguna en tu entorno.
La principal conclusión a destacar en lo que hemos visto es, solo con cambiar de versión y sin tocar una sola línea de código tenemos:
- Batch Mode on rowstore (2019+). Procesamiento en lote de 900 filas frente a procesamiento fila a fila que teníamos con versiones anteriores.
- Scalar UDF Inlining (2019+). Mejoramos el rendimiento de las funciones escalares.
- Table Variable Deferred Compilation (2019+). Mejoras en el uso de variables tipo tabla.
- Cardinal estimator feedback (2022+). Identificación de consultas con problemas de cardinalidad.
- Memory grant feedback (2019+). Autogestión de la asignación de la memoria asignada a consultas, minimizando el uso de almacenamiento en tempdb
- Parameter Sensitivity Plan Optimization (2022+). Ya has visto la demo…. Posibilidad de varios planes de ejecución a una misma consulta parametrizada en función de su cardinalidad.
- Mejoras en el acceso concurrente a archivos del sistema (2022+). Mejora significativa en las operaciones que requieren acceso a disco.







