
El Web Scraping es una técnica de obtención de datos de páginas web. Existen variedad de usos; algunos de los más extendidos pueden ser el de motores de búsqueda para analizar webs y clasificarlas, o portales de compras que chequean los precios de la competencia para poder tomar decisiones basadas en esa información. Te explicamos como llevarlo a la práctica con Selenium, Python y Beautifulsoup en Azure Data.
¿Qué es el Web Scraping? ¿Cómo podemos sacar partido de esta técnica?
El Web Scraping es una técnica de obtención de datos de páginas web. Existen variedad de usos: algunos de los más extendidos pueden ser el de motores de búsqueda para analizar webs y clasificarlas, o portales de compras que chequean los precios de la competencia para poder tomar decisiones basadas en esa información
¿Cómo podemos hacer Web Scraping?
En este ejemplo, nos vamos a enfocar en el Web Scraping de páginas dinámicas que suele ser el más complicado, ya que si nos conectamos a una de estas webs y obtenemos el código, seguramente nos estemos quedando con solo una pequeña parte de la información que queremos conseguir. Para solucionar esta problemática vamos a utilizar una herramienta llamada Selenium.
¿Qué es Selenium?
Se trata de una herramienta de automatización de testing web que soporta varios de los navegadores más usados del mercado y se puede programar en multitud de lenguajes como pueden ser Java, C#, Python, Ruby, PHP, Perl y JavaScript.
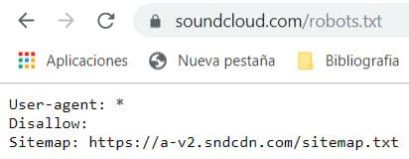
A la hora de hacer Web Scraping de una web nos debemos cerciorar de que no estamos incumpliendo ninguna política de dicha web, para ello podemos revisar el fichero Robots.txt en el cual se nos dará información sobre a qué contenidos vamos a poder acceder.
En este caso vamos a hacer Web Scraping a la página Soundcloud, ya que revisando su Robots.txt deja libre acceso a su web:
Azure Data Studio
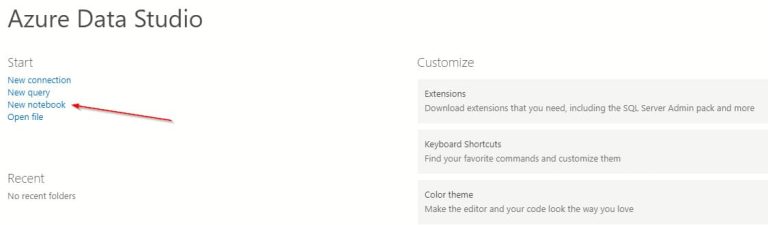
Para ejecutar nuestro script en Python vamos a utilizar Azure Data Studio, ya que nos permite la creación de notebooks de Jupyter y la instalación del kernel es casi totalmente automática y transparente para el usuario. Basta con:
1. Crear un nuevo notebook
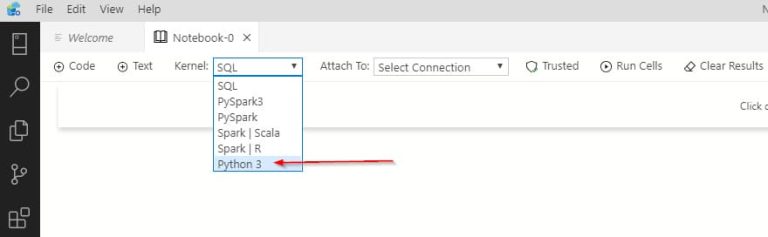
2. Elegir el kernel de Python
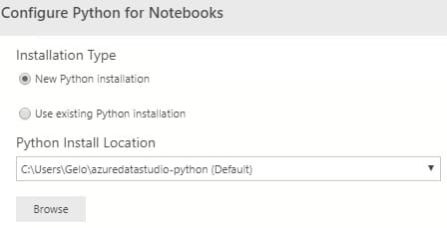
3. Seleccionar si queremos una nueva instalación de Python o usar una ya existente
Ahora el propio Data Studio se encarga de instalar paquetes y librerías necesarios para ejecutar Python y varias librerías de Machine Learning. Solo nos faltaría instalar los paquetes de Selenium, Beautifulsoup4 y cssutils desde la opción Manage Packages:
Por último, también necesitaremos descargarnos el driver de Chrome en este caso y dejarlo en la ruta que se especifica en el script o en otra que consideremos. El driver lo podemos descargar de la siguiente web: https://chromedriver.chromium.org/downloads
Python y BeautifulSoup
En este caso la web de Souncloud es una web de distribución de música online, que nos sirve perfectamente para el ejemplo, ya que su contenido se genera de forma dinámica. Para nuestra prueba vamos a elegir un grupo con muchos álbumes publicados y a lo largo de varias décadas como es Iron Maiden, concretamente en este link podemos ver que necesitamos hacer scroll hasta el final de la página para obtener toda la información.
Nos vamos a quedar por ejemplo con las imágenes de los albums, el nombre y la fecha de publicación, lo vamos a exportar a un fichero y lo vamos a visualizar en PowerBI.
En este caso tenemos un problema a la hora de hacer scroll y es que si vamos demasiado rápido vamos a tener partes de la página que no se van a generar, por lo tanto vamos a tener que hacer un scroll lento mediante un bucle hasta llegar al final de la página.
iter=1
while True:
scrollHeight = driver.execute_script("return document.documentElement.scrollHeight")
Height=250*iter
driver.execute_script("window.scrollTo(0, " + str(Height) + ");")
if Height > scrollHeight:
print('End of page')
break
iter+=1
La idea es ir haciendo scroll con una altura de 250 por cada iteración, que es un scroll que nos garantiza que se genera toda la info que queremos y lo iremos comparando con la altura del documento, cuando nuestra altura sea mayor que la del documento saldremos del bucle.
Otro tema a tener en cuenta, es que no nos vale con quedarnos con el page_source de la página, ya que en este caso nos quedarían ocultos muchos tramos de código. Para ello, nos quedaremos con el html interno del body de la página.
body = driver.execute_script("return document.body")
source = body.get_attribute('innerHTML')
Una vez tenemos el html, una de las mejores formas de analizarlo y sacar datos de él es una librería de Python llamada BeautifulSoup. También vamos a usar otra herramienta para sacar datos de código CSS como es cssutils.
from selenium.webdriver.chrome.options import Options
from selenium import webdriver
from bs4 import BeautifulSoup
import time
import cssutils
import re
# Specifying incognito mode as you launch your browser[OPTIONAL]
option = webdriver.ChromeOptions()
option.add_argument("--incognito")
#we create the driver specifying the origin of chrome browser
driver = webdriver.Chrome("C:/Scraping/chromedriver.exe", chrome_options=option)
driver.get("https://soundcloud.com/ironmaidenmusic/albums")
driver.maximize_window()
time.sleep(1)
#We make a slow scroll to the end of the page
iter=1
while True:
scrollHeight = driver.execute_script("return document.documentElement.scrollHeight")
Height=250*iter
driver.execute_script("window.scrollTo(0, " + str(Height) + ");")
if Height > scrollHeight:
print('End of page')
break
time.sleep(1)
iter+=1
#we get the internal html code of the body
body = driver.execute_script("return document.body")
source = body.get_attribute('innerHTML')
#we create a flat file and write the header
file1 = open("C:\\Scraping\\Files\\Albums.txt","w", encoding='utf-8')
file1.write("Album,Cover,Published"+'\n')
#we iterate through the different albums with beautifulsoup and load the data into the flat file
soup = BeautifulSoup(source, "html.parser")
for album in soup.find_all("li", "soundList__item"):
album_title = album.find("a", class_="sound__coverArt")
album_link = album_title['href']
title = album_title.div.span['aria-label']
style = album_title.div.span['style']
styles = cssutils.parseStyle(style)
url = styles['background-image']
opacity = styles['opacity']
album_date = album.find("div", class_="soundTitle__usernameTitleContainer")
date = album_date.find("span", class_="releaseDateCompact sc-type-light sc-font-light").span.text
if opacity == '1':
file1.write(title+','+url[4:-1]+','+'https://soundcloud.com'+album_link+','+date+'\n')
#finally we close the file and the driver
file1.close()
driver.close()
También se puede ejecutar Selenium en el modo Headless, de esta forma no veríamos cómo se abre un navegador y empieza a iterar por las páginas. Se ejecutaría en segundo plano. Para ello, solo tendríamos que hacer la llamada al driver con la siguiente opción:
option = webdriver.ChromeOptions()
option.add_argument("--headless")
Vemos el script funcionando:
Visualización en Power BI
Una vez tenemos el fichero CSV final lo visualizamos en PowerBI, filtrando los álbumes por fecha de publicación mediante un slicer, para ver las carátulas de los discos utilizaremos un objeto visual llamado Image Grid. De esta forma veremos de una forma muy directa, por ejemplo qué discos había sacado Iron Maiden en la década de los 90.
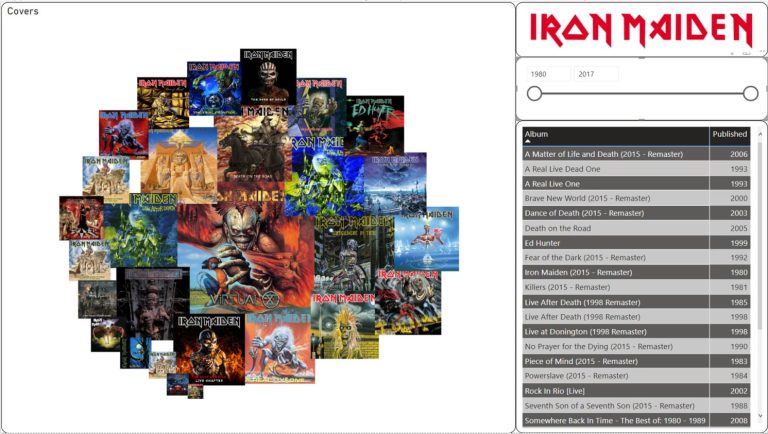
Vemos cómo se comporta el informe:

Conclusión
Esto solo es un ejemplo menor de lo que se puede llegar a hacer con Selenium en combinación con otras herramientas como pueden ser Python y Beautifulsoup. En este caso, para hacer Web Scraping de forma automatizada y obtener datos que de otra forma no seríamos capaces.
Las aplicaciones comerciales de estas técnicas, como ya hemos dicho, son varias pero antes de empezar ningún proyecto de esta índole tendremos que asesorarnos jurídicamente para evitar sorpresas desagradables.







