
Microsoft Fabric y Databricks ofrecen a sus clientes las capacidades para la analítica avanzada de datos en un mundo moderno donde el volumen, la variedad y la velocidad de los datos ha aumentado de forma exponencial. Voy a tratar de analizar 5 aspectos que ponen en valor ambos productos y que permitirá conocer a los lectores el valor que aporta cada uno.
Arquitectura de Microsoft Fabric y Databricks
En cuanto a la arquitectura de los productos, el aspecto más general es que Microsoft Fabric se presenta como un software como servicio (SaaS) mientras que Databricks es una plataforma como servicio (PaaS). Esto permite que con Databricks podamos tener mayor flexibilidad y control sobre aspectos relacionados con la infraestructura, mientras que con Fabric se simplifica la experiencia de usuarios y la administración de la infraestructura. Un punto relevante de Databricks es que está disponible en diferentes nubes como AWS o Azure, mientras que Microsoft Fabric sólo está disponible en Azure.
Mientras Databricks está basado en una versión comercial de Apache Spark, un marco de procesamiento de datos distribuido, Microsoft Fabric contiene esta tecnología como parte de los motores de procesamiento de datos disponibles, y algunas otras que tuvieron su primera versión en otros productos disponibles en la plataforma Microsoft.
En Fabric aparecen conceptos como Warehouse en Fabric, una evolución del pool dedicado de sql de Azure Synapse Analytics o la experiencia de análisis en tiempo real como una evolución de Azure Data Explorer. Mientras que en Databricks con características como Databricks SQL, Streaming Structurated, Databricks AI, entre otras, proporciona a los clientes opciones para todo tipo de experiencias de análisis avanzado de datos.
Databricks fue el pionero en proponer la arquitectura Lakehouse, bastante aceptada y extendida entre las organizaciones, y que ponen a disposición de los clientes el almacenamiento de los datos en diferentes capas dependiendo de la madurez de los datos. Además, adecuado para trabajar con el aumento de variabilidad y volumen de datos de estos últimos años donde los almacenes de datos estructurados no dificultaban el análisis de la información con las recientes tecnologías.
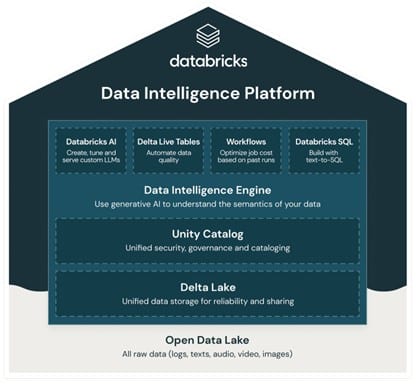
Microsoft Fabric adopta esta propuesta y lo presenta a través de OneLake como capa de almacenamiento de los motores de procesamiento de datos disponibles en el producto y basado en Azure Data Lake Gen2.
En resumen, ambos permiten experiencias para abordar proyectos de ingeniería de datos, analítica avanzada, ciencia de datos, análisis en tiempo real, etc.
Modelo de Precios de Microsoft Fabric y Databricks
Databricks propone un modelo de precio basado en el uso de los recursos que proporciona capacidad de cómputo o de almacenamiento. Desde 0.37€/DBU por hora en la versión estándar del producto hasta 0.501€/DBU por hora en la versión premium. Por ello, no sólo tendremos que conocer el tier y las horas de procesamiento de datos, sino que también tendremos que ver el coste asociado a cada clúster para conocer la factura. Básicamente hay cinco aspectos a valorar:
- DBUs de los clústeres a usar
- Tiempo de procesamiento
- Tier del workspace (estándar o premium)
- Almacenamiento administrado en disco y blobs
- IP pública
Microsoft Fabric propone un cambio de enfoque, también asociado a que se comercializa como software como servicio, en el modo de procesamiento. En este caso el cliente paga por el tiempo que tengas disponible la capacidad de Fabric (en el modo pago por uso), pudiendo usar todas las experiencias dentro de la misma capacidad de Fabric usada. E independientemente del uso que hagas de cada una de ellas o de la posible configuración de computo que puedas personalizar para cada una.
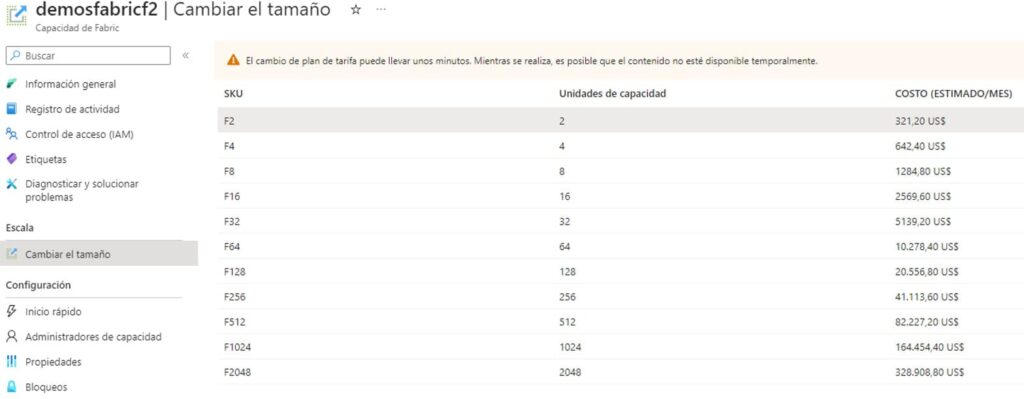
En el modo de pago a través de suscripción es similar a Power BI Premium. Es más, dentro de Power BI Premium ya puedes disponer de las capacidades de Fabric.
En resumen, en Databricks desarrollamos procesos optimizados para que su duración sea la menor posible y así pagar menos, mientras que en Fabric desarrollamos procesos optimizados para que en una carga de trabajo podamos ejecutar la mayor carga de trabajo posible.
Curso de Microsoft Fabric
Usabilidad de Microsoft Fabric y Databricks
La facilidad de uso de los productos se ha vuelto cada vez un aspecto más importante en las plataformas analíticas de datos, y no sólo nos referimos a la experiencia que tienen los usuarios finales en consumir los datos, sino en aspectos tan significativos como simplificar el acceso o integración de los datos necesarios de la organización para trabajar con este tipo de productos. Sobre todo, simplificando aspectos como la integración y acceso a los datos hacemos que los esfuerzos por parte de la organización se centren en obtener el valor necesario de los datos.
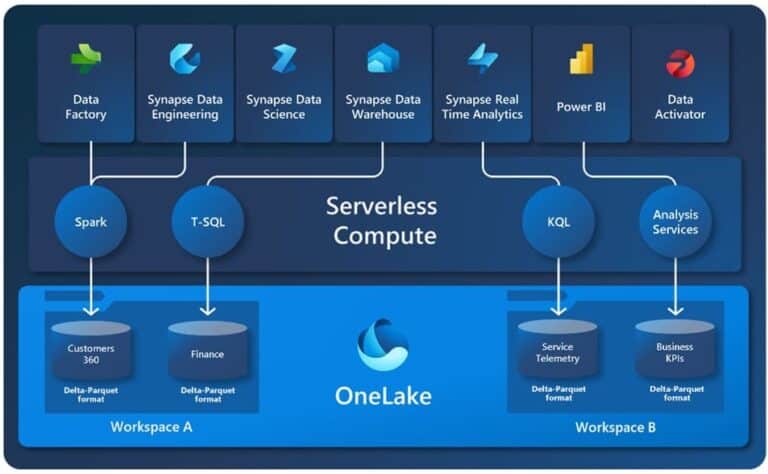
Microsoft Fabric ya dispone de elementos como las canalizaciones y los flujos de datos Gen2 para la ingesta de información que presentan un desarrollo de poco código, que acompañado de los números conectores que posee, facilita los procesos de integración de datos en el OneLake desde otras fuentes. Además, en su roadmap también presenta la característica de Mirroring que permite y permitirá generar procesos de ingesta de datos en el OneLake desde fuentes como CosmoDB, Azure SQL Database, etc.
Podemos encontrar características homólogas en Databricks con las Consultas Federadas, Delta Live Tables o Apache Airflow para el acceso e ingesta de los datos. Aunque estas, presentan una interfaz algo más compleja que la que encontramos en Microsoft Fabric. Databricks anunció a principios de noviembre la adquisición de Arcion con el objetivo de proporcionar de forma nativa una solución escalable, fácil de usar y rentable para ingerir datos en tiempo real y bajo demanda de diversas fuentes de datos empresariales.
Otras características relevantes, que vienen con un impulso marcado por la actualidad, es la utilización del lenguaje natural para consumir o acceder a los datos aprovechando el boom de la IA y de los LLM (Large Language Models). En Microsoft Fabric ya está anunciado que para finales de marzo estará disponible Copilot disponible para apoyar en transformar y analizar información, e incluso generar y crear visualizaciones e informes.
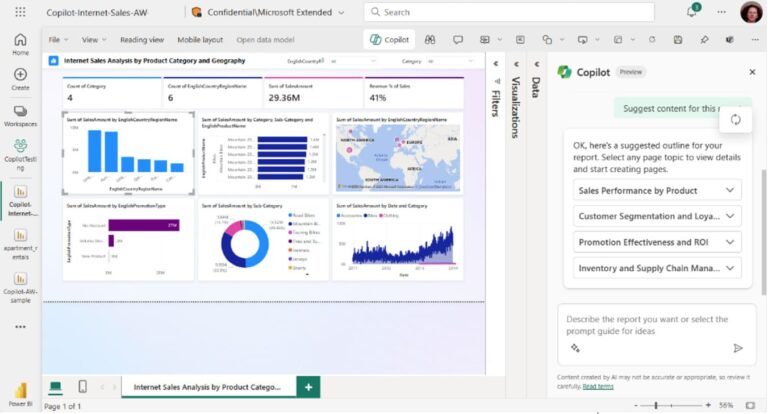
Mientras, Databricks anunciaba en junio LakehouseIQ como un LLM basado en la información sobre los datos, patrones de uso, organigrama del propio cliente, y aprende automáticamente sobre conceptos comerciales y datos del propio cliente.
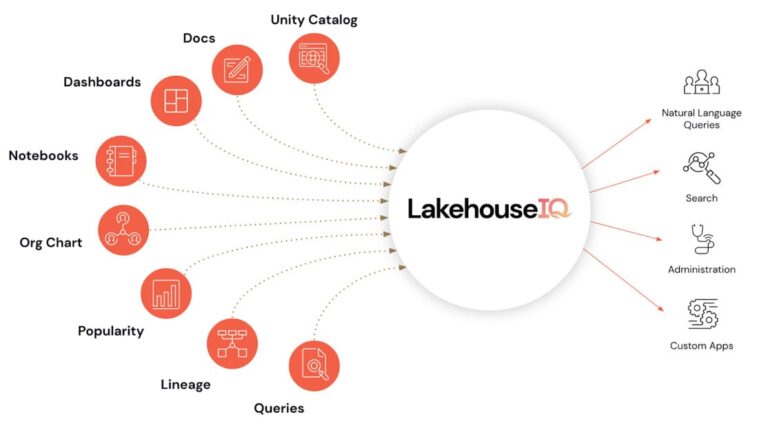
Microsoft Fabric parece tomar un poco de ventaja en la adopción de los usuarios finales con este tipo de agentes en las organizaciones, básicamente porque el entorno de Power BI está bastante adoptado en las organizaciones actuales.
Gobierno del dato en Microsoft Fabric y Databricks
Databricks es pionero con Unity Catalog en aspectos de gobernanza de la arquitectura Lakehouse. Unity Catalog es la solución de gobernanza unificada que permite desde el producto de Databricks hacer un control de acceso fino de los datos y de cualquier activo de IA. Para ello cataloga todos los activos usados dentro de Databricks permitiendo ese modelo de permiso único. Eso sí, siempre que existe en algún área de trabajo de Databricks, o al menos que exista una conexión con la fuente externa. Con esta unificación también permite monitorizar y observar la integración, auditoría y linaje.
Microsoft parece que ha dado una vuelta más para esta parte de gobernanza, también porque amplia la necesidad de administración de todos los activos de datos presentes en la plataforma Azure de la organización. Por un lado, presenta Microsoft Purview como una herramienta para catalogar los activos y donde se pretende centralizar aspectos de cumplimiento, acceso, linaje, compartir, etc. Sin embargo, en Microsoft Fabric como tal, sí que se presentan aspectos de gobernanza centralizados para todos los artefactos disponibles. Basado en la misma idea que Power BI, podemos gestionar accesos y roles a nivel de áreas de trabajo, artefactos (Lakehouse o Warehouse), procesos y está en el roadmap permitir permisos a nivel de carpeta del Lakehouse.
Un poco bajo la experiencia actual parece que tanto Databricks como Microsoft Fabric cumplen con las necesidades iniciales de las organizaciones para la gobernanza contenida dentro del propio producto, y ambos prometen profundizar en estos aspectos para dar una visibilidad completa. Sin embargo, creo que ambos productos necesitan integrarse con Microsoft Purview ya que muchas organizaciones tendrán necesidades más complejas que sólo gestionar un producto u otro. En muchas hay que gestionar un número mayor de recursos desplegados y los cuales disponen de activos de datos.
Combinación de Microsoft Fabric y Databricks
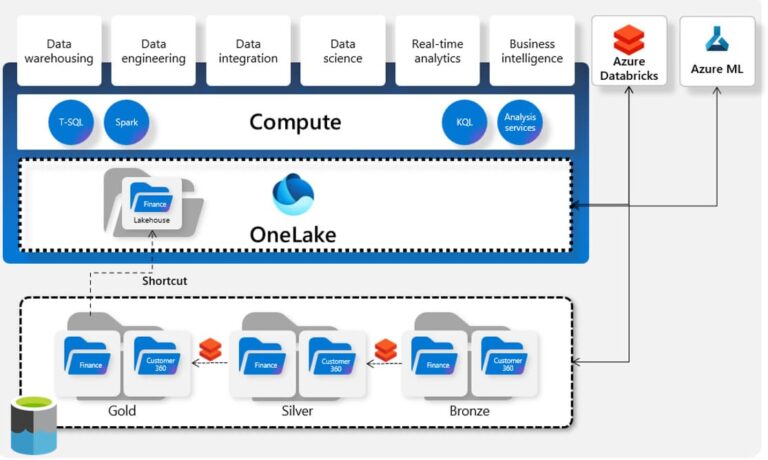
Microsoft Fabric es conocedor que muchos clientes de Azure usan Databricks. Por ello ha destacado desde el principio la integración de ambos productos como una posibilidad o incluso necesidad. Tanto con el acceso directo a un Data Lake ya existe:
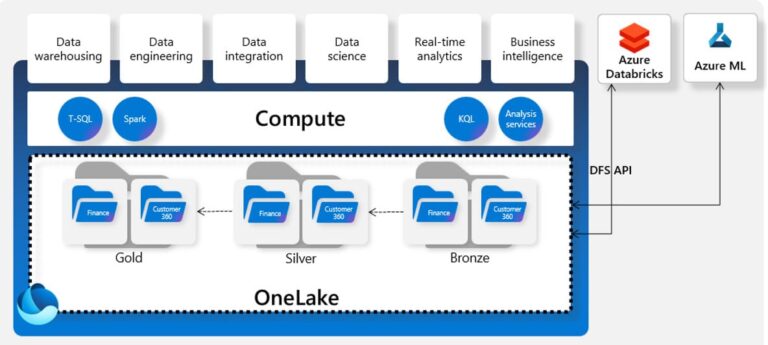
Como con la propia capacidad de utilizar el OneLake directamente para leer o escribir con Databricks:
Inicia tu proyecto de Microsoft Fabric
en tu empresa
¿Hablamos?
Conclusión
Como resumen, ambas soluciones disponen de características que permiten la implementación de una plataforma analítica de datos, sin embargo, hay que tener en cuenta que probablemente en una organización grande convivirán ambos productos. Algunas organizaciones que aborden los proyectos datos quizás prefieran decantarse por saborear más de PaaS (Databricks), ya que quizás por su naturaleza o madurez requiera mayor flexibilidad y administración de la plataforma, y en otras quieran justo lo contrario, minimizar la administración de dicha plataforma apostando por un sabor más SaaS (Microsoft Fabric).
No creo que apostando por ninguna de las dos de entrada un cliente se equivoque, sin embargo, a medida que avancéis es posible que acaben las dos en vuestra suite de productos analíticos usados en la organización.
Muchas características están por llegar y si quieres estar atento a ellas síguenos en las redes. 😊







