
Un escenario bastante habitual en la elaboración de informes es la representación de datos clasificados según sus resultados, estableciendo por ejemplo una escala de eficiencia en las ventas realizadas. Cuestiones como: “¿cuáles son los productos que más se han vendido?”, “¿qué tiendas están contribuyendo de mayor forma a las ventas?” o “¿quiénes son los clientes que más nos compran?” serían ejemplos típicos de este escenario.
¿Cuándo necesitamos un ranking dinámico?
Supongamos que necesitamos mostrar una distribución de las ventas para poder ver de un vistazo cuáles son los productos más vendidos. Algo sencillo, ¿no? Construimos un gráfico de tarta dentro de nuestro informe y he aquí un posible resultado:
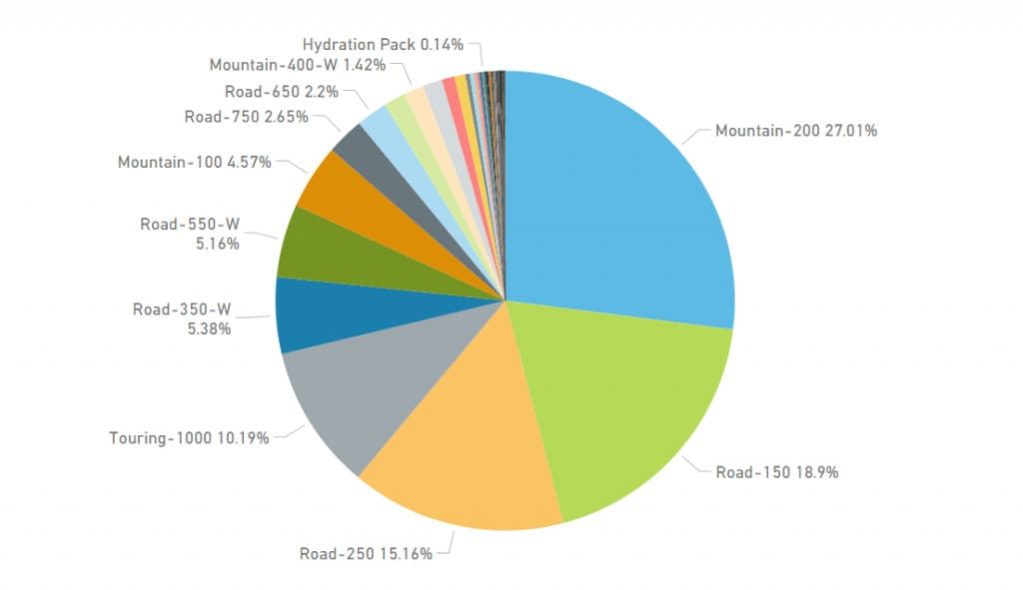
Figura 1. Análisis de ventas segmentadas por producto.
Aunque la distribución para algunos productos puede apreciarse y está clara, tenemos tantos elementos que resulta difícil de leer y diferenciar en la amalgama de colores final. Bueno, que no cunda el pánico, acotemos los resultados a los cinco productos más vendidos:
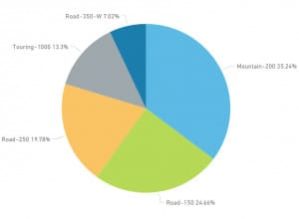
Figura 2. Análisis de los cinco mejores productos con porcentajes
Mucho más limpio y entendible, ¿cierto?. Sin embargo, si nos fijamos en el gráfico, se está omitiendo parte de la información y además se está mostrando como el 100% de las ventas un valor menor al real. Para poder apreciarlo con más claridad, transformemos el gráfico de tarta en uno de barras e incluyamos una tabla con sus resultados junto al total de ventas que tenemos registrados:
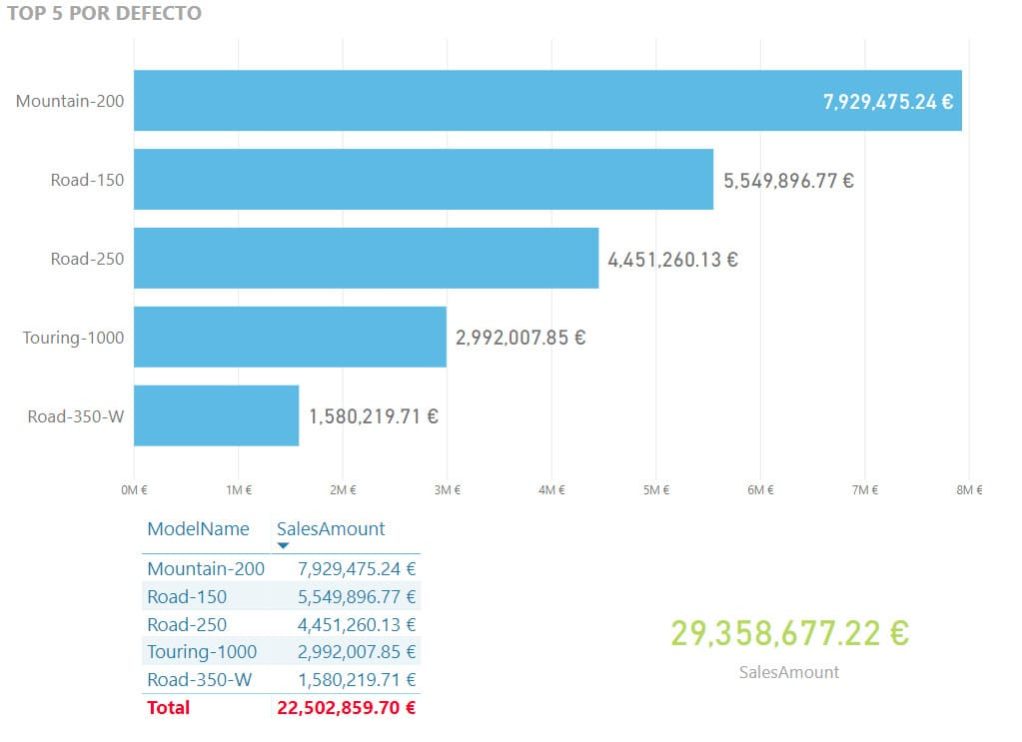
Figura 3. Análisis de los cinco mejores productos incluyendo cifras.
Tal como observamos en la imagen, las cifras, aunque correctas, no suponen el total real del importe de las ventas por lo que puede conducir a errores en la interpretación de los usuarios. Por otro lado, el ranking que hemos definido es estático, si surgiese la necesidad de que la clasificación tiene que verse bajo distintos criterios (los 3/5/10/X mejores) deberemos modificar de forma significativa la plantilla de nuestro informe.
¿Podemos resolver esta problemática con Power BI? La respuesta es sí. En esta entrada, detallaremos como poder elaborar un ranking dinámico donde se muestren tantos elementos como se quieran evaluar junto a los que quedan fuera de la clasificación, que se mostrarán agrupados como uno solo que se etiquetará como resto.
Cómo implementar un ranking dinámico con Power BI
Escenario de trabajo
Para elaborar la solución, partiremos de un modelo muy sencillo compuesto por una tabla de hechos (Sales) y tres dimensiones (Date, Clients y Products).
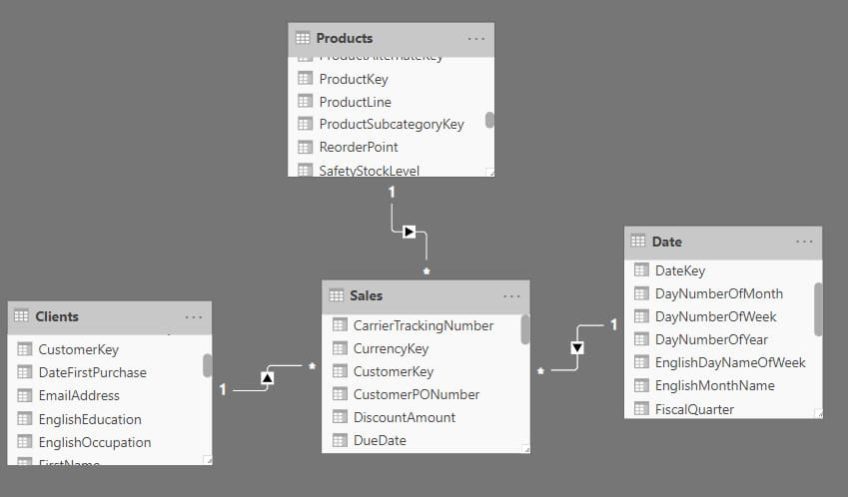
Es importante destacar que el proceso que vamos a detallar es un patrón que puede reutilizarse para varios escenarios y/o diferentes dimensiones, no una solución específica para las características de la dimensión del ejemplo (Products).
Creando el registro para el resto agrupado
El primer paso necesario para poder implementar la solución consistirá en crear el registro físico para el miembro del resto dentro de la dimensión que vayamos a evaluar, lo cual podemos realizar de dos formas:
- Insertamos el registro en nuestro origen de datos, por ejemplo, mediante una instrucción INSERT en BBDD. El dato será consumido como una fila más por Power BI.
- Creamos el registro desde el propio Power BI mediante Power Query.
En nuestro caso, crearemos un registro ficticio de producto con nombre Others dentro de la dimensión Products empleando la segunda opción. Para ello, tras haber importado los datos con los que vamos a trabajar y modelar nuestra solución, nos situaremos sobre la opción EditQueries dentro del apartado Home del ribbon de Power BI Desktop:
Dentro de las consultas definidas para nuestro modelo, nos situaremos sobre la consulta Products y añadiremos un nuevo paso llamado Add Others Row donde mediante la función Table.InsertRows crearemos el registro para la agrupación del resto.
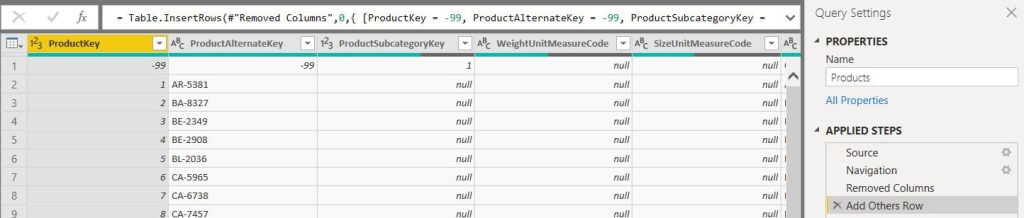
Con esto ya tendremos el registro físico en nuestro modelo, listo para poder emplearse en los cálculos que implementaremos.
Estableciendo los elementos a evaluar
Para poder dotar de dinamismo nuestro ranking, necesitaremos crear una tabla calculada donde establezcamos las distintas combinaciones que precisemos y una medida que nos informe de cuál es la combinación seleccionada por el usuario.
Para la tabla calculada, dispondremos de varias opciones: crearla mediante la opción EnterData de Power BI Desktop, crearla en nuestro origen de datos o (como haremos en nuestro caso) crearla automáticamente en nuestro modelo mediante DAX. Dentro del apartado Modeling escogeremos la opción New Table, tras lo que introduciremos en la barra de fórmulas la sentencia DAX para crear nuestra tabla TopX mediante la función GENERATESERIES():
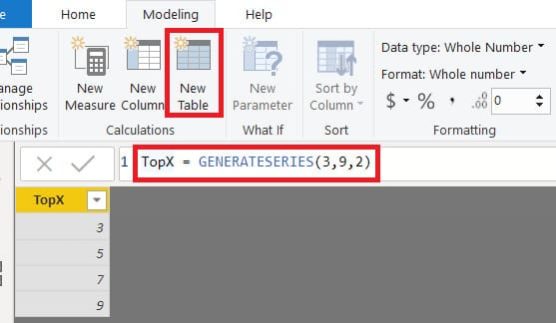
Por lo que respecta a la medida, calcularemos el máximo valor de la tabla TopX de forma que tenga siempre valor tanto si el usuario selecciona un valor como si no hay seleccionado ninguno. Al usar MAX el valor de la medida por defecto se corresponderá con el registro de valor más elevado en la tabla (9 en la figura X):
SelectedTopX :=
MAX ( ‘TopX'[TopX] )
Implementando los cálculos dinámicos
Como último paso, definiremos las dos medidas que haciendo uso de los elementos previamente creados nos permitirán mostrar el ranking de elementos seleccionado incluyendo el conjunto del resto de forma que no se omita información y se mejore su visualización (si es posible).
La primera que definiremos será Ranking, la cual será una medida auxiliar que nos devolverá la clasificación del producto que estemos evaluando (Products[ModelName] en el modelo) sobre la medida que analicemos, en nuestro caso el importe de ventas (SalesAmount) mediante la función RANKX():
Ranking :=
RANKX ( ALL ( Products[ModelName] ), [SalesAmount],, DESC, DENSE )
En segundo lugar, definiremos la medida final TopXPlusOthers, que devolverá los resultados de las ventas para cada producto con un valor de clasificación (obtenido de Ranking) mayor al que estemos evaluando (obtenido de SelectedTopX) y la suma de los resultados para todos aquellos que estén por debajo en el registro creado de Others:
TopXPlusOthers :=
VAR SelectedTop = [SelectedTopX] RETURN
IF (
[Ranking] <= SelectedTop,
[SalesAmount],
IF (
HASONEVALUE ( Products[ModelName] ),
IF (
VALUES ( Products[ModelName] ) = “Others”,
SUMX (
TOPN (
COUNTROWS ( ALL ( Products[ModelName] ) ) – SelectedTop,
ALL ( Products[ModelName] ),
[SalesAmount], 1
),
[SalesAmount] )
)
)
)
Comprobando los resultados
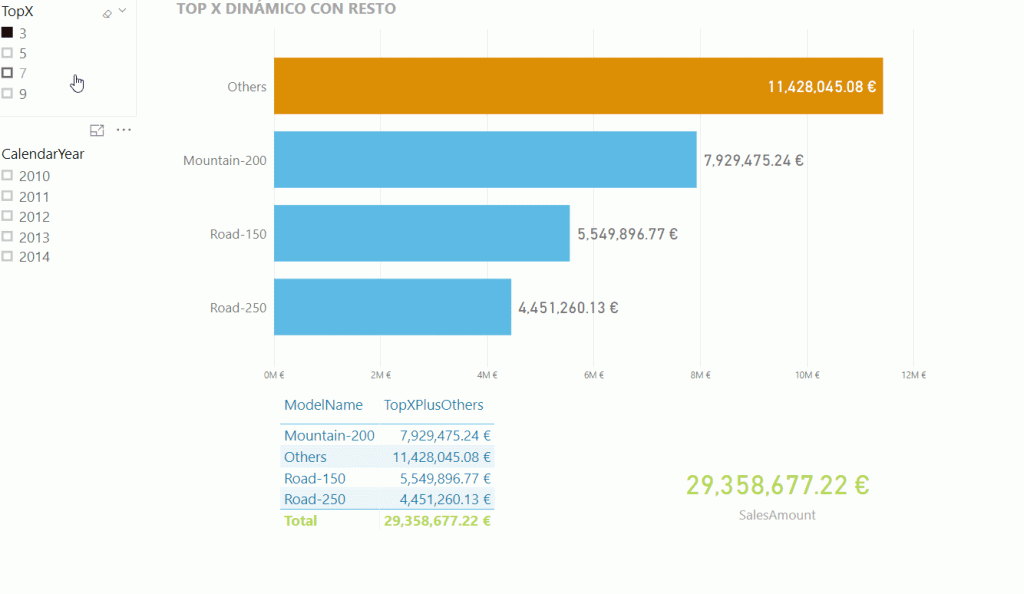
Tras todos los pasos anteriores, ¿qué ocurre si reemplazamos nuestro importe de ventas (SalesAmount) por la nueva medida TopXPlusOthers como valor en los gráficos que hemos visto al principio?
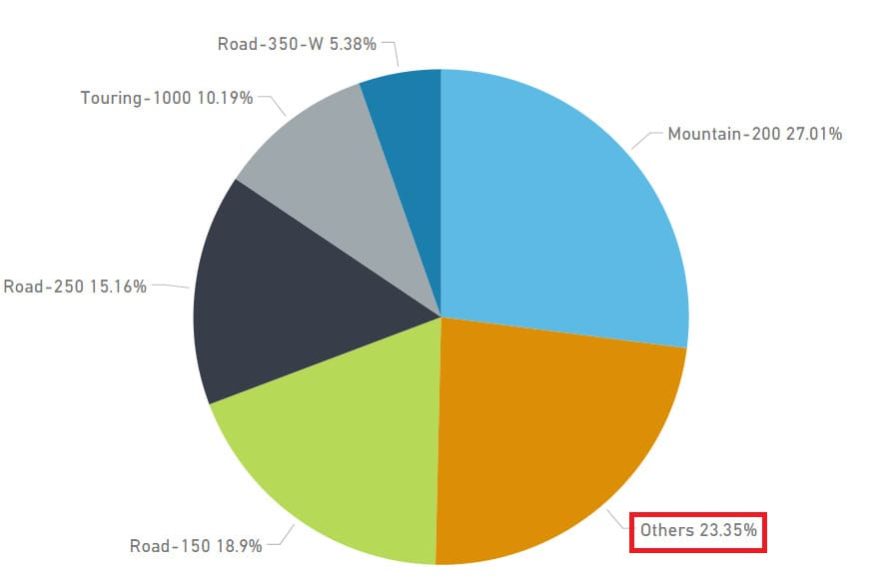
Tenemos una distribución clara y que representa el tanto por cien real. Además, es dinámica y se ajusta a los criterios que indique el usuario.
Conclusiones
Así pues, en esta entrada hemos visto como poder realizar un análisis más detallado para los rankings, en el cual se mostrará el número de elementos escogidos más el resto como uno solo agrupado, simplemente usando métricas y sin necesidad de duplicar la tabla de la dimensión que estamos analizando para incluir el miembro sobre el que agruparemos. Únicamente debemos incluirlo dentro de ella como un registro más.
En caso de que necesitemos aumentar o modificar las combinaciones disponibles para el ranking, bastará solamente con operar sobre la tabla TopX, el resto de elementos no se verán afectados y continuarán funcionando con normalidad. Actualmente, si quisiéramos crear el mismo efecto sobre otras medidas de nuestro modelo distintas de SalesAmount necesitaríamos crear medidas adicionales pero una vez se incorporen los grupos de cálculo dentro de Power BI sería posible realizarlo con un único set de medidas utilizando dicha característica (disponible en SSAS 2019 y Azure Analysis Services).







