
Hoy os ayudamos a crear un report financiero con cuentas aplanadas con Power BI y os explicamos la solución a algunos problemas que pueden surgir basándonos en la experiencia del proyecto real de un cliente.
La representación de las jerarquías de cuentas contables resulta un elemento crítico a la hora de modelar una solución económico-financiera. Power BI, por defecto, visualiza las jerarquías en una matriz de manera que de cada padre se despliegan los hijos, a partir de estos los hijos de los hijos y así sucesivamente.
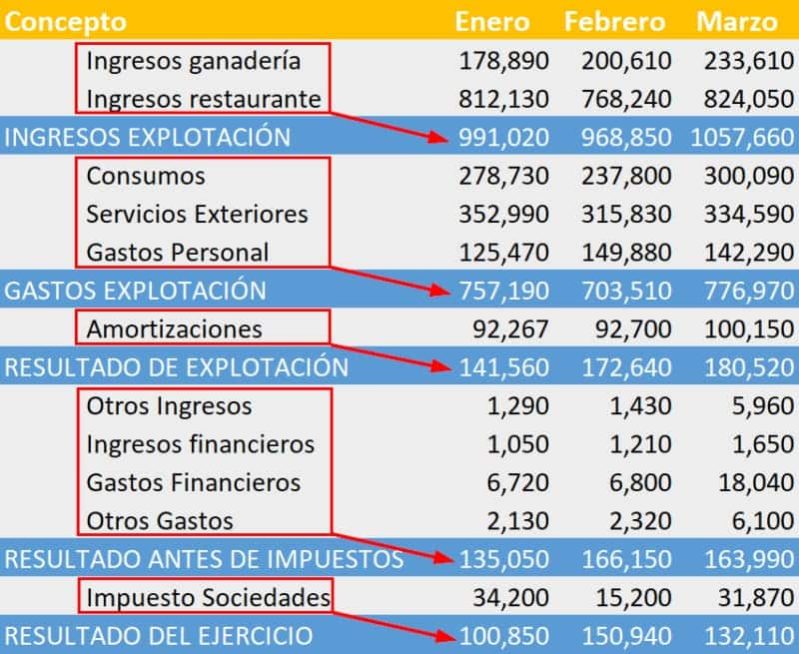
Sin embargo, no siempre se desea ese comportamiento, y es lo que nos ha sucedido hace poco trabajando con un cliente en un reporte contable. La petición era que querían ver las cuentas “hijo” por encima de las líneas de los padres. Lo que viene a ser la representación habitual de los libros de estudio dedicados a la materia.
Además, nos pidió que aplanáramos la jerarquía para los niveles superiores. Por supuesto todo esto se tenía que conseguir sin generar nada estático, se debía mantener la posibilidad de análisis por todas las dimensiones relacionadas a los movimientos.
Disclaimer, no soy contable por lo que puede que mi vocabulario no sea del todo preciso o correcto, pero con las indicaciones del cliente ha quedado todo a su gusto
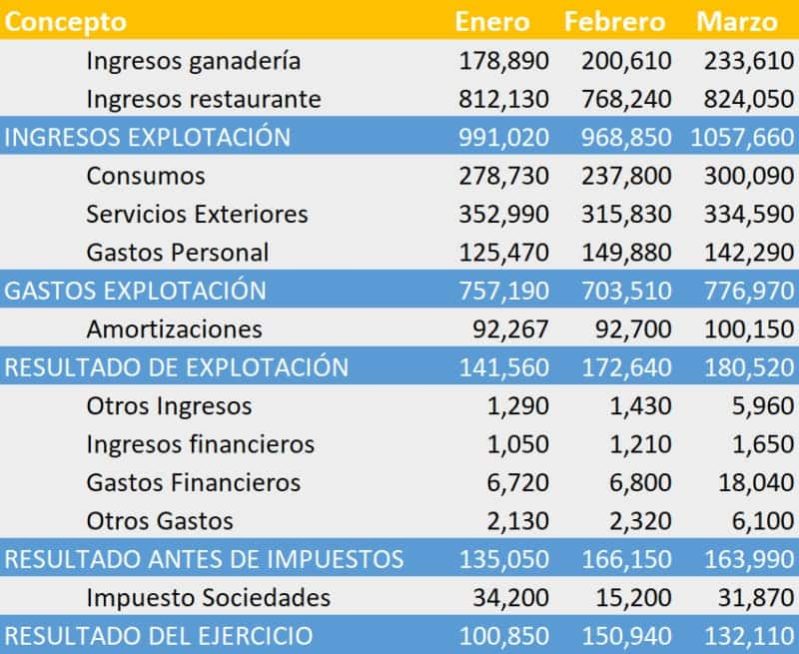
El resultado final ha sido el siguiente:
Por ejemplo en la línea de Total Gastos Explotación* aparecerá la suma de las líneas Consumos, Gastos de personal, Servicios exteriores y Tributos.
* Por confidencialidad los datos se han eliminado
Con números
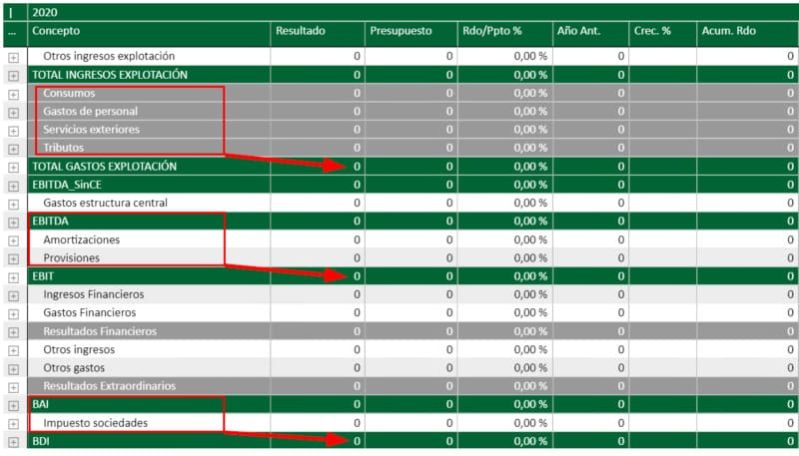
El Ebit sería la suma de lo que ya hubiera en el Ebitda más Amortizaciones y Provisiones, el Bai lo que hubiera en Ebit más las líneas Ingresos y Gastos (excepto resultados, que son solo para análisis) etc. Además, para algunas líneas se puede pulsar sobre el símbolo del más y desplegar los hijos para ir al detalle (sobre todo es útil en las líneas del Total de Ingresos y Gastos de explotación para llegar a las cuentas finales)
En este blog, no queremos entrar en el detalle exhaustivo de cómo lo hemos logrado ya que daría para unas cuantas publicaciones. Vamos a utilizar un ejemplo sencillo que nos permita explicaros el “core” de la técnica empleada:
Pues vayámonos a la cocina y empecemos con la receta.
Cursos de Power BI
Cómo construir una jerarquía y aplanarla
El primer paso va a ser construir una jerarquía (en un sistema real la extraeríamos del origen) y aplanarla. Esta sería la relación de cuentas:
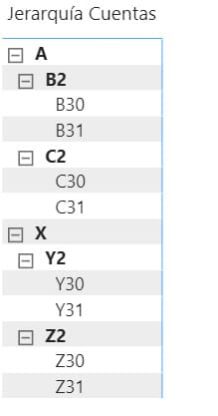
Los sistemas analíticos no se suelen llevar muy bien con las relaciones padre-hijo, así que lo que se suele hacer es poner cada nivel como una nueva columna, a esto me refiero con aplanarla. Quedaría algo así:
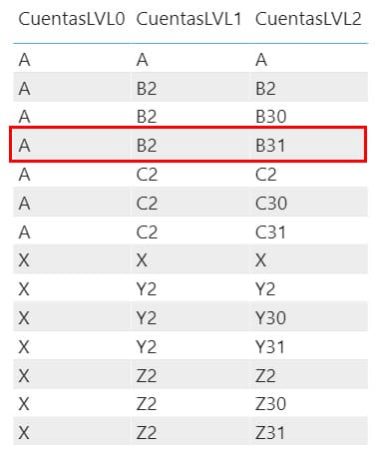
Si observamos el ejemplo de la línea resaltada nos proporciona la misma información que la captura anterior en la relación padre-hijo: B31 es hija de B2 que a su vez lo es de A.
Vemos como algunas líneas como las del valor X o A se repite en cada nivel, es una manera de indicar que hablamos de esas cuentas y no de sus hijos. Si en una tabla de movimientos nunca se referencian directamente a los niveles padres no es necesario tenerlo, por ejemplo, un directivo que nunca hace ingresos por ventas de electrodomésticos, solo sus empleados, pero queremos analizar las ventas totales de todas las personas a su cargo. No es nuestro caso, las necesitaremos para hacer agregaciones hacia ellas sin tener los hijos (más adelante lo detallaremos). El código SQL para construirla es el siguiente en donde además tendremos los ID de las cuentas y de sus padres
WITH Cuentas as (
SELECT IDCuentaPadre, IDCuenta, Cuenta
FROM (values
( 20, 1, ‘B30’) –Su padre es B2
,( 20, 2, ‘B31’) –Su padre es B2
,( 21, 3, ‘C30’) –Su padre es C2
,( 21, 4, ‘C31’) –Su padre es C2
,(125, 5, ‘Y30’) –Su padre es Y2
,(125, 6, ‘Y31’) –Su padre es Y2
,(126, 7, ‘Z30’) –Su padre es Z2
,(126, 8, ‘Z31’) –Su padre es Z2
,(100, 20, ‘B2’) –Su padre es A
,(100, 21, ‘C2’) –Su padre es A
,(150, 125, ‘Y2’) –Su padre es X
,(150, 126, ‘Z2’) –Su padre es X
,(NULL,100, ‘A’)
,(NULL,150, ‘X’)) a(IDCuentaPadre,IDCuenta,Cuenta)
), Recursiva AS (
SELECT IDCuenta, Cuenta,
IDCuenta as LVL0, Cuenta as CuentasLVL0,
IDCuenta as LVL1, Cuenta as CuentasLVL1,
IDCuenta as LVL2, Cuenta as CuentasLVL2,
0 AS NumberLevel
FROM Cuentas
WHERE IDCuentaPadre is null
UNION ALL
SELECT Child.IDCuenta
,Child.Cuenta
,Parent.LVL0, parent.CuentasLVL0,
(case when (Parent.NumberLevel<1) then Child.IDCuenta else Parent.LVL1 end) as LVL1,
(case when (Parent.NumberLevel<1) then Child.Cuenta else parent.CuentasLVL1 end) as DescLVL1,
(case when (Parent.NumberLevel<2) then Child.IDCuenta else Parent.LVL2 end) as LVL2,
(case when (Parent.NumberLevel<2) then Child.Cuenta else parent.CuentasLVL2 end) as DescLVL2,
(Parent.NumberLevel + 1) as NumberLevel
FROM Recursiva Parent
INNER JOIN Cuentas Child
ON Child.IDCuentaPadre = Parent.IDCuenta
)
SELECT [IDCuenta], [Cuenta], [LVL0], [CuentasLVL0], [LVL1], [CuentasLVL1], [LVL2], [CuentasLVL2], [NumberLevel]+1 AS [NumberLevel]
FROM recursiva
ORDER BY IDCuenta desc
No voy a entrar en detalles de la parte de la recursividad en la CTE, pero en resumen lo que hace es coger los casos base, todas aquellas cuentas que no tiene padre, e ir añadiéndoles hijos en cada bucle de la llamada. Hay que repetir cada columna por cada nivel que tengamos. El resultado:
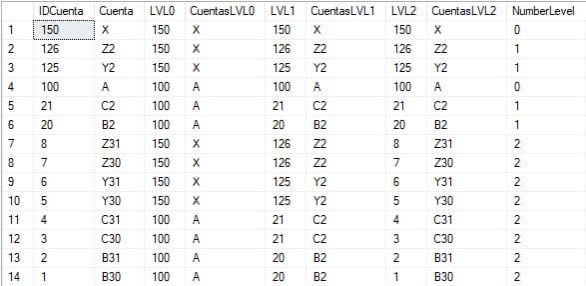
Si esto lo cargamos en Power BI nos queda lo siguiente:
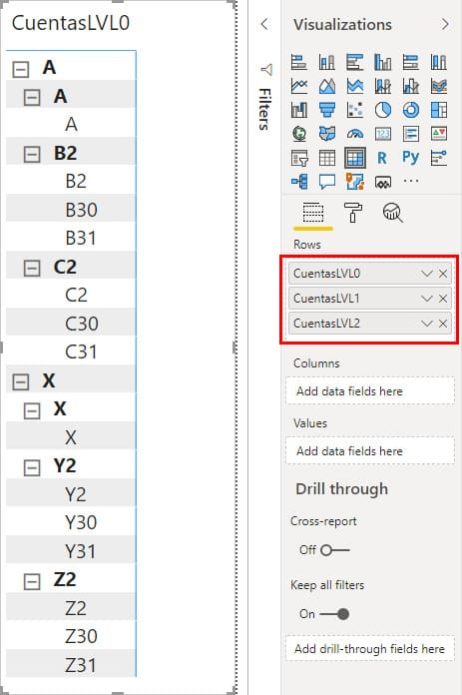
Vamos a asignar valores a las cuentas para ver como queda con números. Construimos una tabla con el siguiente código:
SELECT Fecha,IDCuenta,Cantidad
FROM (VALUES
(‘2020-11-01’,1,100) –Suma a la cuenta: B30
,(‘2020-11-01’,2,100) –Suma a la cuenta: B31
,(‘2020-11-01’,3,100) –Suma a la cuenta: C30
,(‘2020-11-01’,4,100) –Suma a la cuenta: C31
,(‘2020-11-01’,5,100) –Suma a la cuenta: Y30
,(‘2020-11-01’,6,100) –Suma a la cuenta: Y31
,(‘2020-11-01’,7,100) –Suma a la cuenta: Z30
,(‘2020-11-01’,8,100) –Suma a la cuenta: Z31
,(‘2020-11-01’,100,1000)–Suma a la cuenta: A
) a(Fecha,IDCuenta,Cantidad)
Como se puede ver en la última línea le estamos asignado 1000€ a la cuenta A, que no es un hijo para ver como aparece representada en Power BI:

Los totales de cada nivel son correctos, y vemos como en la cuenta X, al no tener ningún valor asignado directamente a ella se muestra sin problemas. Por el contrario, como A si tiene 1000€ directamente a ella se despliega la jerarquía y se repite tantas veces como niveles tengamos. En este caso puede no ser muy molesto, pero teniendo en mente el reporte que queremos hacer si que puede darnos algún dolor de cabeza. Para quitarlo crearemos dos medidas en la tabla de Cuentas
(CuentasEjemplo en el código)
Min Depth = MIN (CuentasEjemplo[NumberLevel] )
Current Hierarchy Depth =
ISFILTERED ( CuentasEjemplo[CuentasLVL0] )
+ ISFILTERED ( CuentasEjemplo[CuentasLVL1] )
+ ISFILTERED ( CuentasEjemplo[CuentasLVL2] )
La segunda podría escribirse con la función IsInScope pero si el usuario filtra la tabla no va a funcionar correctamente en todos los casos.
Si añadimos estas dos medidas a la matriz podemos analizar un poco más que hace cada una:
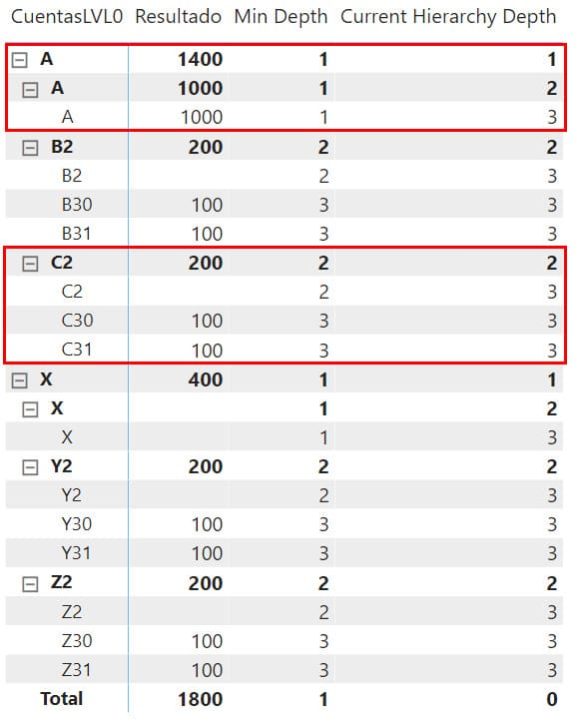
Min Depth nos dice a qué nivel pertenece cada cuenta. Por ejemplo, en A siempre nos dice que es una cuenta de primer nivel mientras que en el caso de C2 (que recordemos que también cuelga de A) nos indica en que nivel está ella misma y cada una de sus hijas.
CurrentHierarchy nos dice siempre en nivel real (columna de la jerarquía) estamos representando. Algún lector puede haber sido consciente de que al final de la CTE recursiva añadí al NumberLevel un +1, es para que aquí ambas medidas empiecen en 1, si no Min Depth empezaría en 0. Además, esto nos permitiría quitar el Gran Total de la matriz por código y no depender de que el usuario lo haga. ¿Por qué vamos a querer quitar el gran total? Si recapacitamos sobre lo que hemos pintado, en realidad hay dos jerarquías independientes, A y X. Una de ellas podría estar representando valores que no permitan agregarse a la otra en el total a la otra jerarquía (p.e., Monedas, porcentajes, escalas etc)
Evitaremos que A se repita cuando le asignamos una cantidad a ella directamente con la siguiente fórmula de agregación en vez de un simple sumatorio:
Resultado Sin Hijos =
IF (
[Min Depth] >= [Current Hierarchy Depth],
sum(Movimientos[Cantidad])
)
Y si quisiéramos quitar el Total con la medida:
Resultado Sin Hijos = IF([Current Hierarchy Depth] = 0, BLANK(),
IF (
[Min Depth] >= [Current Hierarchy Depth],
sum(Movimientos[Cantidad])
))
Voilà, A ya no aparece por triplicado pero agrega correctamente (su total sigue teniendo los 1000€ que le habíamos asignado) y tampoco tenemos el Total (si queremos quitar la palabra total es hacerlo en las propiedades de la matriz de PBI, pero no deshabilitando el Row Subtotals, solo el de CuentasLVL0 después de tener Per row Level habilitado, si no tendremos problemas) ¡Esto mejora por momentos!
Un apunte más, si tuviéramos operador unario deberíamos cambiar ese sum(Movimientos[Cantidad]) por la lógica de sumas por niveles que requiere.
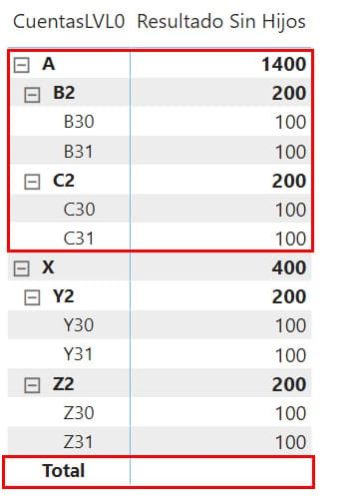
Ahora queremos que B2 y C2 aparezcan independizadas de A, que es su madre, pero sin que A pierda el total de estas cuentas (vamos, que siga diciendo que tiene 1400). Y puestos a pedir, que Y2 y Z2 hagan lo mismo con X. Para conseguir esto tenemos que decir que los IDPadre de estas cuentas sean NULL… ¡Espera! Si hacemos esto entonces decimos que A ya no es su madre. Por si alguien se ha perdido, teníamos la siguiente relación para B31

Y estamos hablando de hacer

¡Entonces A ya no agregará todo lo que dependa de B2! Ok, correcto, ¿pero y si duplicamos la jerarquía desde el nivel 3? Algo así

Todo valor asignado a la cuenta B31 sumará hacia B2 y por otro lado hacia A. Resumiendo, vamos a construir distintas jerarquías por cada línea del reporte que queramos representar independientemente de la siguiente manera
WITH Cuentas as (
SELECT IDCuentaPadre,IDCuenta,Cuenta
FROM (values
(20,1,‘B30’)
,(20,2,‘B31’)
,(21,3,‘C30’)
,(21,4,‘C31’)
,(25,5,‘Y30’)
,(25,6,‘Y31’)
,(26,7,‘Z30’)
,(26,8,‘Z31’)
,(100,20,‘B2’)
,(100,21,‘C2’)
,(105,25,‘Y2’)
,(105,26,‘Z2’)
,(NULL,100,‘A’)
,(NULL,105,‘X’)) a(IDCuentaPadre,IDCuenta,Cuenta)
UNION ALL
SELECT *
FROM (VALUES
(NULL,20,‘B2’)
,(NULL,21,‘C2’)
,(NULL,125,‘Y2’)
,(NULL,126,‘Z2’)
) a(IDCuentaPadre,IDCuenta,Cuenta)
), Recursiva AS (
SELECT IDCuenta, Cuenta,
IDCuenta as LVL0, Cuenta as CuentasLVL0,
IDCuenta as LVL1, Cuenta as CuentasLVL1,
IDCuenta as LVL2, Cuenta as CuentasLVL2,
1 AS NumberLevel
FROM Cuentas
WHERE IDCuentaPadre is null
UNION ALL
SELECT Child.IDCuenta
,Child.Cuenta
,Parent.LVL0, parent.CuentasLVL0,
(case when (Parent.NumberLevel<1) then Child.IDCuenta else Parent.LVL1 end) as LVL1,
(case when (Parent.NumberLevel<1) then Child.Cuenta else parent.CuentasLVL1 end) as DescLVL1,
(case when (Parent.NumberLevel<2) then Child.IDCuenta else Parent.LVL2 end) as LVL2,
(case when (Parent.NumberLevel<2) then Child.Cuenta else parent.CuentasLVL2 end) as DescLVL2,
(Parent.NumberLevel) as NumberLevel
FROM Recursiva Parent
INNER JOIN Cuentas Child
ON Child.IDCuentaPadre = Parent.IDCuenta
)
SELECT [IDCuenta], [Cuenta], [LVL0], [CuentasLVL0], [LVL1], [CuentasLVL1], [LVL2], [CuentasLVL2], [NumberLevel]+1 AS [NumberLevel]
FROM recursive
La parte que ha cambiado es esta
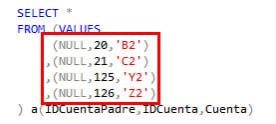
Es probable que en un sistema real esto no lo escribamos a mano, tengamos una tabla de mapeos, un identificador o algo similar.
Carguemos estos datos en PBI ¡Cuidado!, la relación ha cambiado, ahora debe ser una M:M entre la tabla de cuentas y la tabla de Movimientos.
Ahora en nuestra matriz tenemos lo siguiente
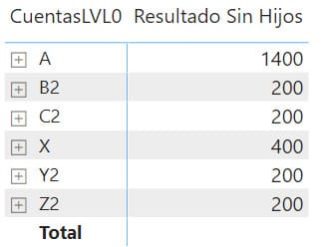
Pinta bien, pero queremos que A esté debajo de B2 y C2 y lo mismo con Y2, Z2 respecto a X. Ordenémoslos. Como son mis datos ya me he dejado preparaditos los números de cuentas para que al ordenarlos salgan como queremos, pero en el entorno real seguramente tengamos que pensar algo más elaborado.
A la última consulta SQL del código anterior añadiré justo antes del FROM Recursiva una columna nueva:
,LVL0 AS Orden
Con esta me quedo con el ID del nivel más alto de cada línea que pertenezca a la misma jerarquía. Ordenamos la columna CuentasLVL0 por Orden y ya queda el nivel superior como queríamos. (Sí, realmente podríamos haber ordenado por LVL0, pero como decía, esto no pasará en un entorno real, hay que añadir una columna de Orden)
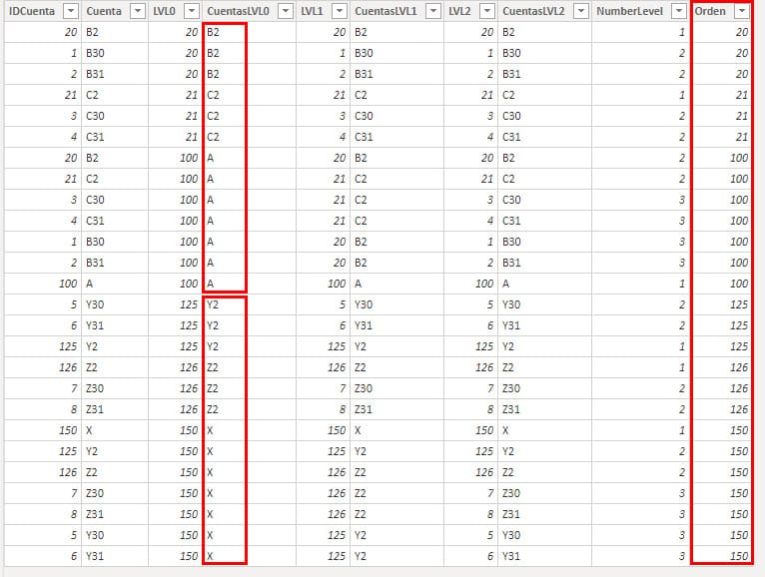
En nuestra matriz del reporte quedará así
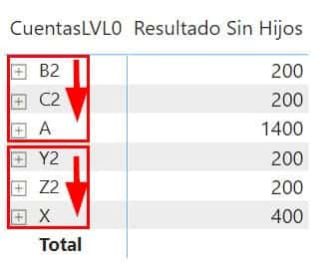
Ah, pero queda todo alineado a la izquierda, no da lugar a interpretar que es una jerarquía fácilmente y tampoco donde acaba cada una. ¡Podríamos añadirles espacios en blanco a los nombres! Spoiler: no va a funcionar. PBI los quita, pero existe un carácter especial llamado Non-breaking space (nbsp) (que cuando te aparece en una carga de datos suele dar un dolor de muelas horrible y le odias con toda tu alma porque para más inri aparentemente no se diferencia de un espacio) que no se quita. En SQL es el char(160). Si concatenamos 3 de estos al nombre de cada jerarquía se van a tabular hacia la derecha.
El UNION ALL que teníamos antes lo modificaremos a lo siguiente
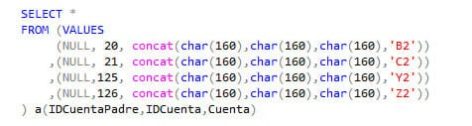
El código quedaría de la siguiente manera
WITH Cuentas as (
SELECT IDCuentaPadre, IDCuenta, Cuenta
FROM (values
( 20, 1, ‘B30’) –Su padre es B2
,( 20, 2, ‘B31’) –Su padre es B2
,( 21, 3, ‘C30’) –Su padre es C2
,( 21, 4, ‘C31’) –Su padre es C2
,(125, 5, ‘Y30’) –Su padre es Y2
,(125, 6, ‘Y31’) –Su padre es Y2
,(126, 7, ‘Z30’) –Su padre es Z2
,(126, 8, ‘Z31’) –Su padre es Z2
,(100, 20, ‘B2’) –Su padre es A
,(100, 21, ‘C2’) –Su padre es A
,(150, 125, ‘Y2’) –Su padre es X
,(150, 126, ‘Z2’) –Su padre es X
,(NULL,100, ‘A’)
,(NULL,150, ‘X’)) a(IDCuentaPadre,IDCuenta,Cuenta)
UNION ALL
SELECT *
FROM (VALUES
(NULL, 20, concat(char(160),char(160),char(160),‘B2’))
,(NULL, 21, concat(char(160),char(160),char(160),‘C2’))
,(NULL,125, concat(char(160),char(160),char(160),‘Y2’))
,(NULL,126, concat(char(160),char(160),char(160),‘Z2’))
) a(IDCuentaPadre,IDCuenta,Cuenta)
), Recursiva AS (
SELECT IDCuenta, Cuenta,
IDCuenta as LVL0, Cuenta as CuentasLVL0,
IDCuenta as LVL1, Cuenta as CuentasLVL1,
IDCuenta as LVL2, Cuenta as CuentasLVL2,
0 AS NumberLevel
FROM Cuentas
WHERE IDCuentaPadre is null
UNION ALL
SELECT Child.IDCuenta
,Child.Cuenta
,Parent.LVL0, parent.CuentasLVL0,
(case when (Parent.NumberLevel<1) then Child.IDCuenta else Parent.LVL1 end) as LVL1,
(case when (Parent.NumberLevel<1) then Child.Cuenta else parent.CuentasLVL1 end) as DescLVL1,
(case when (Parent.NumberLevel<2) then Child.IDCuenta else Parent.LVL2 end) as LVL2,
(case when (Parent.NumberLevel<2) then Child.Cuenta else parent.CuentasLVL2 end) as DescLVL2,
(Parent.NumberLevel + 1) as NumberLevel
FROM Recursiva Parent
INNER JOIN Cuentas Child
ON Child.IDCuentaPadre = Parent.IDCuenta
)
SELECT [IDCuenta], [Cuenta], [LVL0], [CuentasLVL0], [LVL1], [CuentasLVL1], [LVL2], [CuentasLVL2], [NumberLevel]+1 AS [NumberLevel]
,LVL0 AS Orden
FROM recursive
En el reporte
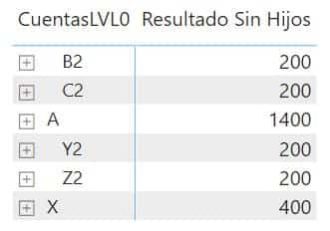
Estupendo, ya queda visualmente correcto. ¿hemos acabado? Pues depende, si queremos que al desplegar A nos diga que sus cuentas hija son B2 y C2 sí, pero si es algo que ya conocemos y que además gráficamente ya se ve, entonces aún nos queda algo de trabajo.
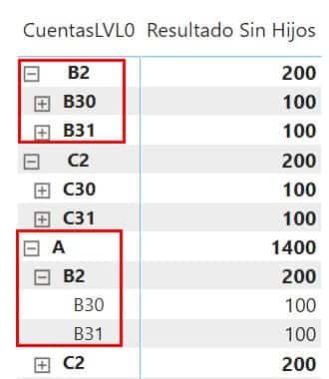
Podríamos simplemente quitar los dos últimos niveles de la matriz
Pero entonces no vamos a poder ver quiénes son los hijos de B2 y C2 y en algunos casos igual si queremos desplegarlos.
Volvamos a la mesa de trabajo y planteémonos qué queremos conseguir. Necesitamos que todas las cuentas hijas de A y X agreguen a estas cuentas (a su ID, al que aparecía como A, A, A o X X X en nuestra jerarquía aplanada) directamente pero a la vez se comporten de la manera normal con las cuentas que hemos independizado en su propia jerarquía (B2, C2, Y2, Z2) , esto es, que los movimientos asignados a esas cuentas sigan apuntando al ID de la cuenta original.
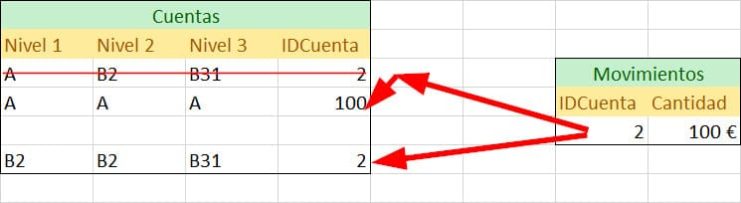
Tabla de mapeo
Para hacer esto vamos a construir una tabla de mapeo pero antes definiremos en la propia tabla de cuentas un identificador del padre de la jerarquía. En el ejemplo anterior tenemos dos veces el ID 2 que corresponde a B31, y esta cuenta agrega por un lado hacia A y por otro a B2, pues vamos a dar un ID único a cada uno de los B31 (y a todas las cuentas repetidas).
En nuestra consulta para generar las cuentas, al final, junto a la columna que hemos creado de Orden añadiremos una nueva
(cast(IDCuenta AS BIGINT) + 10000000) * 10000 + cast(LVL0 AS BIGINT) IDJerarquiaCuentas
La fórmula es solo para desplazar los dígitos de IDCuenta hacia los cuatro de mayor peso y los restantes de menos peso nos indicarán el ID de la cuenta Padre. Solo se hace para que siga siendo un entero y los cruces sean más rápidos, pero se puede hacer como una cadena de texto: “B31 – A”
Queda así la consulta:
WITH Cuentas as (
SELECT IDCuentaPadre, IDCuenta, Cuenta
FROM (values
( 20, 1, ‘B30’) –Su padre es B2
,( 20, 2, ‘B31’) –Su padre es B2
,( 21, 3, ‘C30’) –Su padre es C2
,( 21, 4, ‘C31’) –Su padre es C2
,(125, 5, ‘Y30’) –Su padre es Y2
,(125, 6, ‘Y31’) –Su padre es Y2
,(126, 7, ‘Z30’) –Su padre es Z2
,(126, 8, ‘Z31’) –Su padre es Z2
,(100, 20, ‘B2’) –Su padre es A
,(100, 21, ‘C2’) –Su padre es A
,(150, 125, ‘Y2’) –Su padre es X
,(150, 126, ‘Z2’) –Su padre es X
,(NULL,100, ‘A’)
,(NULL,150, ‘X’)) a(IDCuentaPadre,IDCuenta,Cuenta)
UNION ALL
SELECT *
FROM (VALUES
(NULL, 20, concat(char(160),char(160),char(160),‘B2’))
,(NULL, 21, concat(char(160),char(160),char(160),‘C2’))
,(NULL,125, concat(char(160),char(160),char(160),‘Y2’))
,(NULL,126, concat(char(160),char(160),char(160),‘Z2’))
) a(IDCuentaPadre,IDCuenta,Cuenta)
), Recursiva AS (
SELECT IDCuenta, Cuenta,
IDCuenta as LVL0, Cuenta as CuentasLVL0,
IDCuenta as LVL1, Cuenta as CuentasLVL1,
IDCuenta as LVL2, Cuenta as CuentasLVL2,
0 AS NumberLevel
FROM Cuentas
WHERE IDCuentaPadre is null
UNION ALL
SELECT Child.IDCuenta
,Child.Cuenta
,Parent.LVL0, parent.CuentasLVL0,
(case when (Parent.NumberLevel<1) then Child.IDCuenta else Parent.LVL1 end) as LVL1,
(case when (Parent.NumberLevel<1) then Child.Cuenta else parent.CuentasLVL1 end) as DescLVL1,
(case when (Parent.NumberLevel<2) then Child.IDCuenta else Parent.LVL2 end) as LVL2,
(case when (Parent.NumberLevel<2) then Child.Cuenta else parent.CuentasLVL2 end) as DescLVL2,
(Parent.NumberLevel + 1) as NumberLevel
FROM Recursiva Parent
INNER JOIN Cuentas Child
ON Child.IDCuentaPadre = Parent.IDCuenta
)
SELECT [IDCuenta], [Cuenta], [LVL0], [CuentasLVL0], [LVL1], [CuentasLVL1], [LVL2], [CuentasLVL2], [NumberLevel]+1 as NumberLevel
,(cast(IDCuenta AS BIGINT) + 10000000) * 10000 + cast(LVL0 AS BIGINT) IDJerarquiaCuentas
,LVL0 AS Orden
FROM recursive
Ahora vamos con la tabla de mapeo. Si las cuentas padre son A o X haremos que todas sus cuentas hijas apunten a ellas con el nuevo IDJerarquiaCuentas. Si no, que sigan con su ID. En el ejemplo es muy sencillo poner la condición del IFF, pero en el desarrollo que hicimos es donde estaba gran parte del juego (de hecho, creamos alguna columna más en Cuentas para dar soporte a este cálculo). El código
SELECT IDCuenta
,IIF(lvl0 in (100,150)
,(cast(LVL0 AS BIGINT) + 10000000) * 10000 + cast(LVL0 AS BIGINT)
,(cast(IDCuenta AS BIGINT) + 10000000) * 10000 + cast(LVL0 AS BIGINT)) IDJerarquiaCuentas
FROM Cuentas
Otra nota sobre el operador unario en este punto. Si lo tenemos es probable que tengamos que añadir aquí lógica en una nueva columna para que al agregar una cuenta hija directamente a una cuenta de primer nivel el signo de la agregación sea el correcto.
A la hora de importarlo a PBI podemos dejarlo como una tabla independiente o integrarlo en la tabla de Cuentas. Para fines didácticos vamos a dejarlas independientes. Las relaciones entre tablas quedarían ahora así:
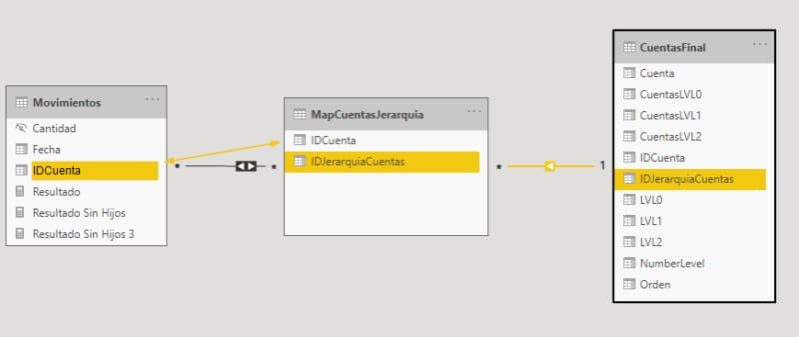
¡Finalizado!
Si lo representamos todo en una matriz veremos la siguiente imagen:
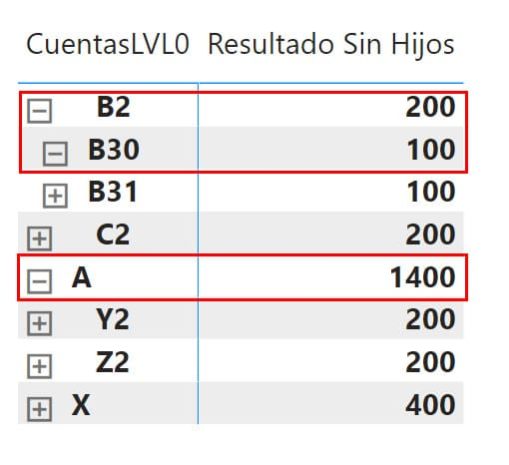
La cuenta A no se despliega más, aunque lo intentemos (el negativo de la cajita), B2 solo se despliega hasta el siguiente nivel y todas las cifras cuadran.
¡Fin! Solo quedaría dar colores y formatos para dejarlo más atractivo.







