
En este artículo haremos un repaso por 10 librerías Python de uso diario en proyectos de Data Science y Aprendizaje Automático. Entre las tareas que realizamos como Científico de Datos o como Ingenieros en Machine Learning, debemos hacer análisis exploratorio de datos, limpieza, preprocesado, modelado, ingeniería de características, selección del mejor modelo, entrenamiento, validación y test, implementación del servicio. Para todas estas tareas contamos con paquetes de software que nos facilitan conseguir nuestros objetivos.
Bootcamp Data Science y Python
Las 10 librerías Python seleccionadas son:
- Pandas
- Numpy
- Plotly
- Scikit-learn
- Category-encoders
- Imbalance Learning
- LightGBM / XGBoost
- Keras / Tensorflow
- Shap
- AzureML-sdk
Hay muchísimas otras librerías Python de interés, que hoy no comentaremos en este artículo, pero les dejo un listado por si quieren curiosear:
Características de estas librerías Python
Vamos a ver sus características una a una:
1- Pandas: Manejo de datos
Pandas es hoy en día una de las librerías más usadas en Data Science pues nos facilita mucho el manejo de datos. Con ella podemos leer archivos ó bases de datos de múltiples fuentes (csv, sqlite, sqlserver, html) y hacer operaciones entre las columnas, ordenar, agrupar, dividir, pivotar, totalizar. Nos ayuda a detectar valores nulos, detectar ouliers, duplicados y también hacer merge ó joins entre distintos orígenes. También nos permite guardar fácilmente nuestro nuevo dataset.
2- Numpy: Operar matrices
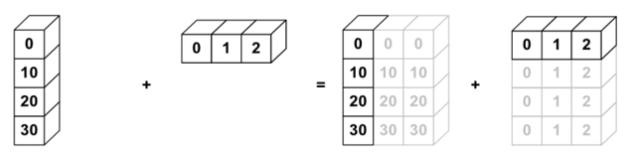
Numpy es un estándar en Python y de hecho es utilizada como base por Pandas y por muchas otras librerías que se apoyan en ella para operar.
Numpy nos permite crear todo tipo de estructuras numéricas, múltiples dimensiones, permite transformarlas, operar aritméticamente, filtrar y es útil muchas veces para la inicialización de datos aleatorios.
3- Plotly: Imagen y clic
Al realizar gráficas y visualización de los datos, muchas veces al momento de realizar el Análisis exploratorio ó al estudiar los resultados obtenidos solemos utilizar el standard Matplotlib.pyplot que realmente es muy buena librería. Sin embargo, echamos de menos no poder “pasar el cursor” por encima de la gráfica e interactuar. También está Seaborn que embellece y expande mucho el alcance de Matplot. Pero nos quedamos con Plotly que con relativamente poco esfuerzo nos regala gráficas clicables, que nos aportan mayor información y nos ayudan en nuestra labor diaria.
4- Scikit Learn: Machine Learning en tu mano
Esta librería creció y creció y cada vez cubre más de nuestras necesidades al momento de preprocesar datos, hacer transformaciones y crear modelos de ML. De hecho, muchas de las nuevas librerías que aparecen siguen sus interfaces para implementar su código. ¿Te suenan los métodos fit(), transform(), predict()? Ó el muy usado train_test_split? Todos vienen de aquí!
Una de las funciones que más me gustan de sklearn, es la de crear Pipelines para las transformaciones y poder reutilizarlos. No hay que perder de vista que para proyectos empresariales los datos que nos llegan “en crudo” deberán ser transformados siempre de la misma manera para alimentar a los modelos de ML.
Por otra parte, sklearn cuenta con implementaciones de los algoritmos <<clásicos>> para clasificación, regresión y clusterización: Regresión Lineal / Logística, Support Vector Machines, K Nearest Neighbors, Procesos Gaussianos, Naive Bayes, Árbol de decisión, PCA, y modelos de Ensamble.
Habría mucho más que decir sobre sklearn, pero por el momento aquí lo dejamos.
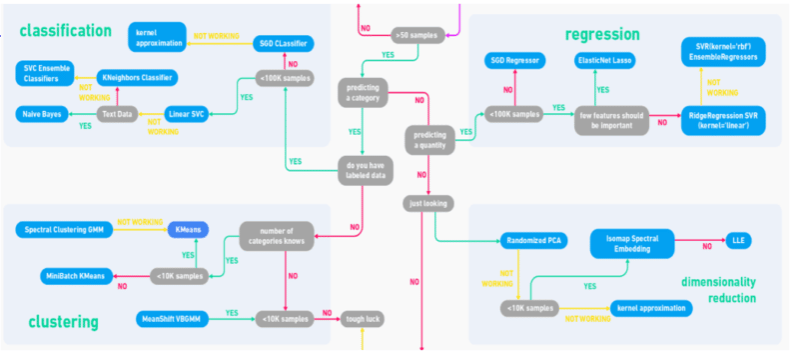
5- Category Encoders: Mejora del Dato
Esta librería es muy útil para intentar dar significado a datos categóricos. Suele ocurrir que entre nuestras variables tenemos valores “A,B,C” ó nombre de zonas, ó diversas categorías “Alto, medio, bajo” que para ser utilizadas en modelos de ML deberemos convertir en valores numéricos. Pero… ¿asignaremos 1,2,3 para “ABC” sin que esto tenga ninguna lógica? ¿ó descartamos esas variables? ¿Valores aleatorios?
Mejor dejarle la tarea a Category Encoders. Nos ofrece diversas transformaciones para dar valor a esas variables categóricas y asignarles un “peso” que pueda aportar valor y significado al momento de entrenar el modelo.
Este paso puede ser tan valioso que podría marcar la diferencia para conseguir unas buenas predicciones.
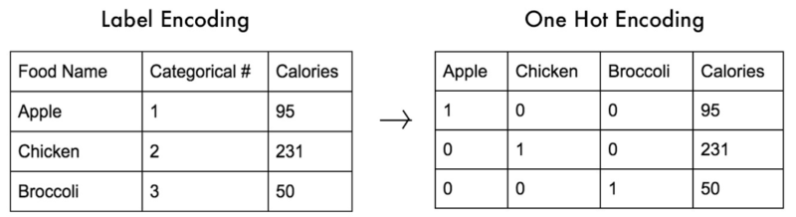
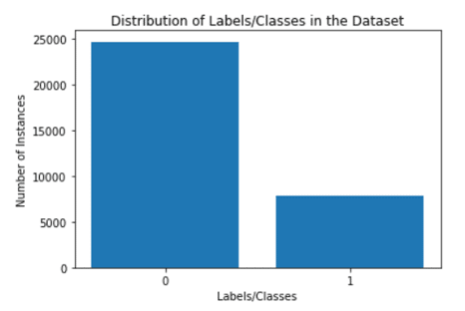
6- Imbalance Learning: Emparejar los datos
Otro caso que se da con mucha frecuencia al hacer tareas de clasificación es contar con una cantidad desbalanceada de muestras de cada clases. Casos típicos son la detección de alguna enfermedad en donde la mayoría de las muestras son negativas y pocas positivas o en set de datos para detección de fraudes.
Para que un algoritmo supervisado de ML pueda aprender, deberá poder generalizar el conocimiento y para ello, deberá de <<ver>> una cantidad suficiente de muestras de cada clase ó será incapaz de discernir.
Allí aparece esta librería al rescate con diversos algoritmos para el re-muestreo de nuestra información. Con ello podremos disminuir al conjunto mayoritario (sin afectar al resultado del entrenamiento), aumentar al conjunto minoritario (creando muestras artificiales “con sentido”) ó aplicar técnicas combinadas de oversampling y subsampling a la vez.
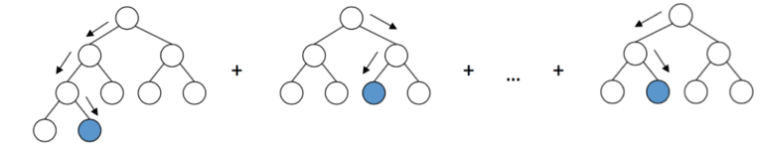
7- LightGBM / XGBoost: Árboles con potencia
Los modelos de sklearn de ML están bien, pero… qué pasa si necesitamos “algo más potente” que un árbol de decisión? pues allí aparecen modelos novedosos como LightGBM ó XGboost.
Utilizan técnicas de “Gradient Boosting” (es decir, optimizar una función objetivo para ponderar el valor de los árboles creados y mejorar así el resultado) pero varían en la manera en que generan los árboles (priorizando niveles ú hojas) y eso afecta a la velocidad de ejecución, aunque son razonablemente rápidas las dos librerías.
LightGBM es mantenida por Microsoft y cuenta con implementaciones para C, Python y R. Puede ejecutar en paralelo y cuenta con soporte a GPU logrando mayores velocidades sobre todo en datasets grandes.
8- Keras/Tensorflow: Deep Learning en pocas líneas
¿Y cuando necesitamos más potencia aún? Allí aparece el Deep Learning…
Sus librerías más populares son Tensorflow y PyTorch, son muy buenas, potentes y optimizadas (¿dije Open-Source = gratuito?).
En este caso, me quedo con Keras que es una librería de Alto Nivel para crear y utilizar Redes Neuronales con Tensorflow como backend.
Es decir, que nos ayuda a poder crear nuestros modelos de Redes Neuronales de una manera simple sin tener que programar directamente con Tensorflow.
Con Keras podremos crear redes multicapa, redes convolucionales, Autoencoders, LSTM, RNN y muchas otras arquitecturas en pocas líneas.
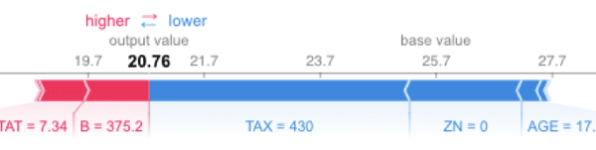
9- Shap: Intepretación de modelos
Al volverse más complejos los modelos de ML y con la aparición de las redes neuronales profundas, se hizo cada más más difícil, si no imposible poder explicar porqué un modelo de ML estaba pronosticando sus resultados de una manera u otra. Esto se volvió un inconveniente pues… ¿podemos confiar en esos resultados? ¿Cómo saberlo?
Para explicar las predicciones de los modelos de ML aparecieron diversas soluciones, siendo una de las más sorprendentes la que se apoya en la “Teoría de Juegos” e intenta contabilizar cuánto aporta cada variable a la predicción final (Shapley values). Nos permite tener una comprensión Global del modelo pero también local, es decir, de cada predicción.
10- Azure ML Sdk: Implementación ML en la Nube
Finalmente presentamos AzureML SDK que nos provee de muchísimas herramientas para trabajar con Data Science y ML, además de permitir implementar nuestro propio servicio en la nube.
Quería destacar que podemos subir a entrenar nuestros modelos de ML en la nube y aprovechar el paralelismo que nos da su Cluster de Computación -en la nube-. Podemos elegir entre decenas de configuraciones de máquinas con mayor CPU, RAM, GPU y disco.
De esta manera, estaremos ejecutando en muchos nodos a la vez, ahorrando tiempo y dinero (pay-per-use).
Además podemos programarlos y automatizar tareas de extracción de datos, preparación del dataset ó entrenamiento de modelos con la frecuencia que sea de nuestro interés.
Por ejemplo, para un servicio meteorológico podríamos hacer que dispare las predicciones a cada hora y que las escriba en una base de datos, que notifique por email ó que escriba en un archivo de logs.
Estas fueron las 10 mejores librerías Python seleccionadas de 2022, Ya veremos cómo evolucionan y cuales ganarán el podio el año que viene!
Otras librerías Python de interés
- Scipy
- joblib
- Matplotlib / Plotly / Seaborn
- Eli5
- Statsmodels
- Runipy / IPython
- Xlsxwriter
- Tqdm
- Sphinx
- Pytest
- Dask
- Pytorch
- Bokeh
- NLTK
- SpaCy
- Gensim
- Pattern
- Scrapy
- BeautifulSoap
- Selenium
- Django
- Flask
- Arrow (para fechas)
- Parsedatetime
- Scikit-image






